Как удалить дубли страниц
Обновлено: 30.12.2021
Многие блогеры ищут ответ на такой вопрос: «Как избавиться от дублей страниц?», для того, чтобы удалить дубли страниц своего сайта из результатов выдачи поисковых систем. Дублированные страницы попадают в индекс поисковых систем, где они присутствуют наряду с основной продвигаемой страницей.
Таких страниц может быть очень много, при этом, поисковая система должна будет ранжировать одинаковые страницы в поисковой выдаче. За это поисковая система может наложить санкции на основную страницу, понижая ее в поисковой выдаче. Таким образом, дубли страниц оказывают вредное воздействие на продвижение страниц сайта в поисковой системе.
- Моя история борьбы с дублями страниц
- Поиск дублей страниц
- Запрет на индексацию в файле robots.txt
- Добавление параметра replytocom в инструменты для веб-мастеров
- Плагин WordPress Thread Comment для древовидных комментариев
- Плагин WordPress SEO by Yoast для удаления replytocom
- 301 редирект для удаления replytocom
- Настройки SEO плагина
- Удаление дублей страниц вручную
- Как удаляются дубли на моем сайте
- Еще один способ для борьбы с дублями страниц
- Выводы статьи
Дублированные страницы могут копировать полное содержание, или только частичное содержание основной страницы. В частности, CMS WordPress сама создает, в некоторых случаях, дублированные страницы, например, всем известный «replytocom» (комментарий, ответ на комментарий, реплика).
Если на вашем сайте включены древовидные комментарии, то в этом случае, каждый комментарий будет создавать дубль страницы. Поэтому, если дубли страниц сайта присутствуют в индексе поисковых систем, то тогда необходимо будет удалить такие страницы из результата выдачи поисковиков.
Поисковая система Google обращает особое внимание на наличие дублей страниц, понижая позиции сайта при наличии большого их количества. Я не буду больше теоретизировать на эту тему, а лучше расскажу вам о том, как я борюсь с дублями страниц, на примере своего сайта — vellisa.ru.
Моя история борьбы с дублями страниц
В самом начале весны 2013 года моему сайту исполнился год, в это время посещаемость сайта составляла примерно 2000 посетителей в сутки. Затем посещаемость на сайте начала резко падать. Уже в середине мая посещаемость едва превышала 1000 посетителей в сутки.
Весной 2013 года у многих блогеров, в связи с вводом новых алгоритмов, понизилась посещаемость с Гугла. На моем сайте посещаемость с поисковика Google уменьшилась примерно на 40%. В моем случае, на спад посещаемости повлиял ввод новых алгоритмов, а также некоторые изменения, которые я сделал в то время на своем сайте.
Подумав, я решил вернуть прежнюю посещаемость для своего сайта. За лето я выполнил эту задачу, в сентябре моему сайту удалось опять выйти на среднюю посещаемость в 2000 посетителей в сутки. Далее посещаемость моего сайта продолжила увеличиваться.
Вроде бы все хорошо, но дело в том, что рост посещаемости произошел, в основном, за счет поисковой системы Яндекс. Если раньше соотношение посетителей пришедших на сайт с поиска Яндекса и Google, было 3 к 1 (примерное соотношение, грубо) в пользу Яндекса, что примерно соответствует доле поисковых систем в Рунете, то затем такое соотношение возросло до 5 к 1. Появилась сильная зависимость от одной поисковой системы.
Посещаемость с Гугла росла очень медленно, только весной 2014 года она достигла уровня прошлого года. А ведь в это время, целый год, я писал новые статьи. Получается, что Яндекс адекватно реагировал на добавление новых статей на сайте, чего не скажешь о Google.
В декабре 2013 года мне пришлось установить на свой сайт новый шаблон, так как на прежней теме, у меня не получалось изменить структуру своего сайта. Эти действия мне необходимо было сделать в любом случае.
После этого я обратил внимание на дублированные страницы в индексе поисковых систем. До этого я знал об этой проблеме, читал о способах ее решения, но пока ничего не предпринимал.
Я, в любом случае, не стал бы отключать на своем сайте древовидные комментарии, потому что из-за этого будет неудобно посетителям сайта, а также я не хотел использовать плагины для удаления дублей страниц.
В итоге, в файл htaccess был установлен код, а из файла robots.txt были удалены некоторые директивы (подробнее, что я делал, расскажу ниже). Постепенно, в результатах выдачи поисковых систем уменьшилось количество дублированных страниц моего сайта.
В марте 2014 года я добавил параметр «replytocom» в инструменты для веб-мастеров Google, а в мае я добавил туда еще один параметр: «feed».
На данный момент, на моем сайте не осталось дублей страниц в результатах выдачи поисковой системы Google, которые имеют в своем адресе переменную replytocom, а ведь раньше таких страниц там было огромное количество (несколько тысяч).
Наконец, я был приятно удивлен возросшей, примерно в 2 раза посещаемостью с Гугла. Теперь соотношение между поисковыми системами стало около 2 к 1 в пользу Яндекса.
Таким образом, на собственном опыте, я узнал о том, какое влияние может оказать на продвижение сайта, наличие дублей страниц в индексе поисковой системы.
Правда, здесь необходимо будет учитывать, что поисковые системы ранжируют страницы в результатах выдачи по многим параметрам. Поэтому у вас, может быть, не произойдет значительный рост посещаемости вашего сайта. В любом случае, удаление дублей страниц из результатов поисковой выдачи, скажется благоприятно на вашем сайте.
Поиск дублей страниц
Для поиска дублей страниц на своем сайте, введите в поисковую строку такое выражение — «site:vellisa.ru» (вместо «vellisa.ru» введите название своего сайта). Перейдите на последнюю страницу поисковой выдачи, у меня, в данном случае, это 19 страница. Запомните номер этой страницы, чтобы потом вы могли быстро перейти к этой странице.
На последней странице поисковой выдачи, ниже последнего результата выдачи, вы увидите объявление, в котором вам сообщают, что поисковая система скрыла некоторые результаты, которые очень похожи на уже представленные выше. Далее нажмите на ссылку «Показать скрытые результаты».
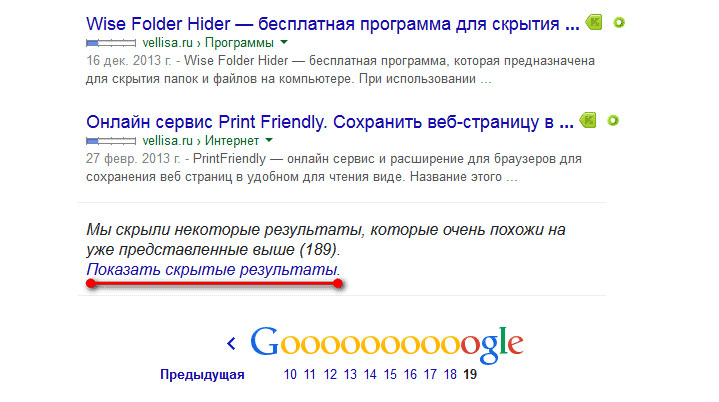
После этого опять будет открыта первая страница поисковой выдачи. Сразу переходите к той странице, которую вы запомнили, в моем случае, это 19 страница. На этой, или на следующей странице, вы увидите дублированные страницы своего сайта.
На этом изображении видны такие дублированные страницы, которые имеют в URL ссылки «feed» и «tag». Также в результатах поисковой выдачи могут присутствовать дубли с «replytocom», «page» и с некоторыми другими параметрами.
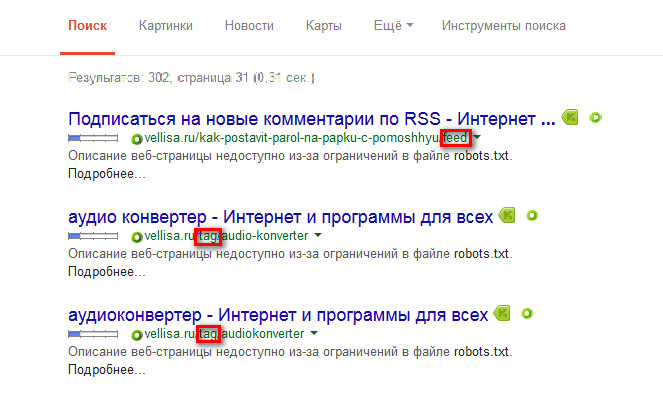
Другой большой проблемой, если на сайте используются древовидные комментарии, является наличие огромного количества страниц с переменной replytocom, которые генерирует сама CMS WordPress.
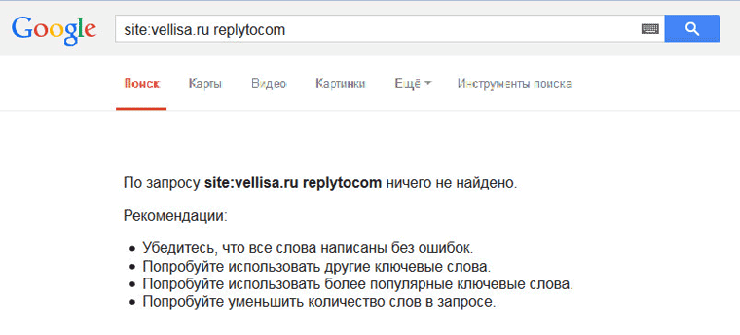
Проверить наличие страниц с replytocom можно таким образом: введите в поисковую строку Google выражение — «site:vellisa.ru replytocom» (без кавычек). Вместо «vellisa.ru» вставьте название своего сайта.
На моем сайте дублированных страниц с replytocom нет, несмотря на то, что на моем сайте присутствуют древовидные комментарии. Для примера я возьму сайт одной моей подруги Юлии (inet-boom.ru), надеюсь, что она за это на меня не обидится.
На этом изображении, в самом конце ссылки, после адреса страницы, вы увидите такое окончание ссылки — «?replytocom=3734». Цифры в конце адреса будут меняться в зависимости от номера комментария.
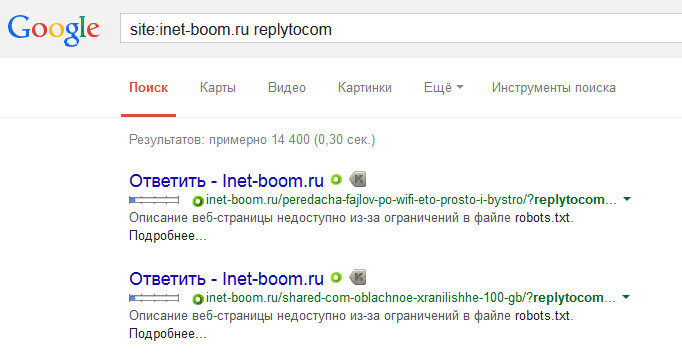
Таких страниц в индексе поисковой системы может быть огромное количество. Поэтому с дублями replytocom нужно будет бороться.
Что необходимо будет сделать?
- Проверить наличие дублированных страниц в индексе поисковых систем.
- Закрыть необходимые параметры от индексации в файле robots.txt.
- Добавить необходимые параметры в панель для веб-мастеров Google.
Эти требования нужно будет выполнить в обязательном порядке. Остальные действия будут зависеть от того способа, который вы выберите для борьбы с дублями страниц.
Вам нужно будет добавить свой сайт в инструменты для веб-мастеров Google и Яндекса, для того, чтобы решать проблему избавления от дублей страниц с помощью этих инструментов поисковых систем.
Запрет на индексацию в файле robots.txt
Для запрета на индексацию определенных параметров, которые оказывают влияние на появление дублированных страниц в поиске, вносятся директивы в файл robots.txt. При использовании директивы Disallow дается команда поисковым роботам для запрещения индексирования.
Команды на запрещение индексации в файле robots.txt могут выглядеть примерно так (на этом примере часть файла):

Директивы со знаком вопроса (?) обычно присутствуют, если на сайте созданы так называемые ЧПУ ссылки, при помощи которых изменяется URL веб-страницы. Здесь также присутствует команда на запрет на индексацию ссылок с переменной replytocom.
Если поисковая система Яндекс, в целом, выполняет директивы, внесенные в файл robots.txt, то с поисковой системой Google все намного сложнее. Роботы Гугла индексируют все, невзирая на запреты, прописанные в файле robots.txt.
В плагинах для SEO оптимизации присутствует возможность закрытия тегом «noindex» рубрик, меток, архивов, страниц поиска и т. д. Правда, не всегда эти указания выполняются поисковыми роботами.
Добавление параметра replytocom в инструменты для веб-мастеров
В Google webmaster tool войдите на страницу «Инструменты для веб-мастеров». В правой колонке «Панель инструментов сайта», сначала нажмите на кнопку «Сканирование», а затем нажмите на кнопку «Параметры URL».
На этой странице вы можете добавить новые параметры или изменить уже добавленные, для обработки поисковыми роботами Google. В зависимости от настроек, поисковый робот Googlebot будет игнорировать определенные параметры при внесении страниц сайта в индекс поисковой системы.
- Для добавления нового параметра нажмите на кнопку «Добавление параметра».

- После этого открывается окно «Добавление параметра».
- В поле параметр (с учетом регистра) добавляете новый параметр, в данном случае «replytocom».
- На вопрос: «Изменяет ли этот параметр содержание страницы, которые видит пользователь?», отвечаете: «Да, параметр изменяет или реорганизует или ограничивает содержание страницы».
- При ответе на вопрос: «Как этот параметр влияет на содержание страницы?», выбираете вариант ответа: «Другое».
- На вопрос: «Какие URL, содержащие этот параметр, должен сканировать робот Googlebot», отвечаете: «Никакие URL».
- Затем нажимаете на кнопку «Сохранить».
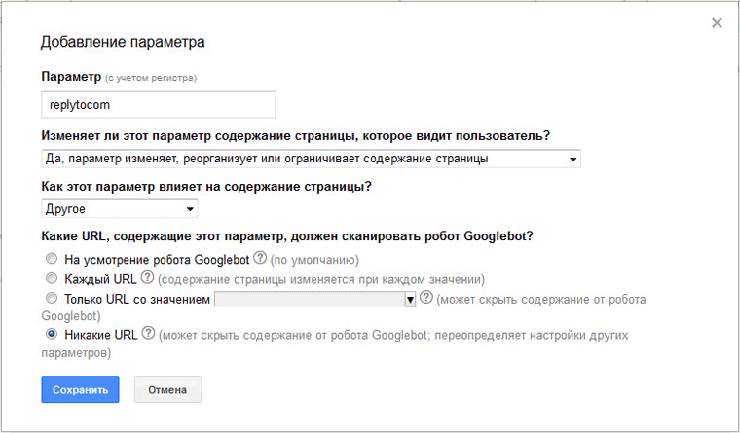
Подобным образом вы можете добавить и другие параметры. Если параметр уже присутствует в списке, то для изменения его настроек необходимо будет нажать на ссылку «Изменить».
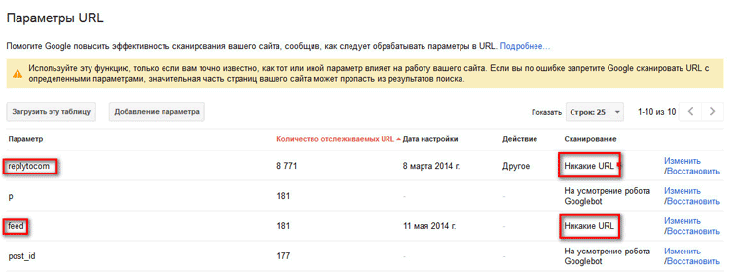
После добавления параметра replytocom в панель для веб-мастеров, из файла robots.txt потребуется удалить примерно такую директиву «Disallow: /*?replytocom» (если она присутствует в файле роботс) для того, чтобы googlebot переходил по ссылкам с этим параметром, и удалял их из индекса.
Если на вашем сайте нет дублей страниц с таким параметром, то тогда вам можно будет оставить такую директиву в файле robots.txt.
Плагин WordPress Thread Comment для древовидных комментариев
Так как, появлению replytocom способствуют древовидные комментарии, то некоторые пользователи вообще отключают их на своем сайте. После отключения древовидных комментариев, особенно, если статьи на сайте активно комментируются, получается очень неудобная навигация. Посетителю, подчас вообще непонятно, кто, где, кому, что ответил.
Плагин WordPress Thread Comment решает проблему древовидных комментариев в WordPress. Древовидные комментарии остаются на сайте, при этом переменные replytocom не добавляются. Плагин выводит ссылку с комментария через javascript, поэтому поисковые роботы не индексируют эту ссылку.
Новые переменные replytocom появляться в индексе поисковика уже не будут, а старые переменные придется постепенно удалить из индекса поисковой системы.
Мне лично в этом плагине не понравился внешний вид комментариев. Я не стал использовать этот плагин на своем сайте. Замечу, что плагин WordPress Thread Comment для борьбы с replytocom, рекомендовал использовать Александр Борисов.
Плагин WordPress SEO by Yoast для удаления replytocom
Плагин WordPress SEO by Yoast, довольно мощный плагин для SEO оптимизации сайта, кроме всего прочего, позволяет удалить с сайта переменные replytocom. При этом, древовидные комментарии останутся на вашем сайте.
После установки плагина WordPress SEO by Yoast на свой сайт, в настройках плагина, в разделе «Постоянные ссылки», необходимо будет активировать пункт «Удалить переменные ?replytocom».
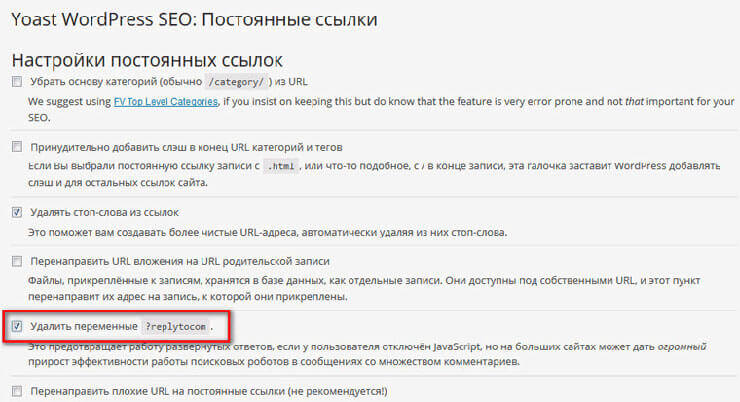
После этого, постепенно дублированные страницы с «соплями» replytocom будут удаляться из индекса Google.
Так как, на моем сайте установлен плагин All in One SEO Pack, и по некоторым причинам, я пока не хочу переходить на плагин WordPress SEO by Yoast, то я не стал использовать этот вариант, для борьбы с дублями страниц.
301 редирект для удаления replytocom
Это, наверное, самый радикальный способ борьбы с replytocom. Я использовал именно этот метод.
После смены шаблона, Лариса Web-Кошка предложила мне использовать 301 редирект для борьбы с дублями replytocom. До смены шаблона на сайте, я не решался использовать этот метод.
Теперь я могу сказать, что при использовании 301 редиректа, а также после некоторых действий, о которых я напишу ниже, мой сайт успешно справился с дублями replytocom.
На этом изображении вы можете увидеть, что на моем сайте нет дублированных страниц с переменной replytocom, несмотря на то, что на моем сайте присутствуют древовидные комментарии, без использования специальных плагинов.
Для использования 301 редиректа потребуется вставить специальный код в файл «htaccess», который находится в корневой папке вашего сайта. Корневая папка сайта — это та папка вашего сайта, в которой находятся папки «wp-admin», «wp-content», «wp-includes» и т. д.
В файл htaccess, ниже строки «RewriteBase /», необходимо будет вставить такой код:
RewriteCond %{QUERY_STRING} replytocom=
RewriteRule ^(.*)$ /$1? [R=301,L]
При возникшей неполадке, вместо своего сайта вы можете увидеть «белый экран смерти». Замена модифицированного файла на оригинальный файл htaccess, вернет работоспособность вашему сайту.
После вставки кода нужно будет проверить работу 301 редиректа. Для этого, сначала необходимо будет вставить в адресную строку браузера ссылку, содержащую replytocom, а затем проверить результат перехода. После перехода, ссылка на открытой веб-странице должна будет поменяться на оригинальную ссылку, не содержащую в URL переменной replytocom.
Далее необходимо будет сделать еще две вещи. Сначала нужно будет удалить из файла robots.txt директивы, содержащие запрет на индексацию страниц со знаком вопроса. Директивы удаляются в том случае, если вы будете использовать этот метод.
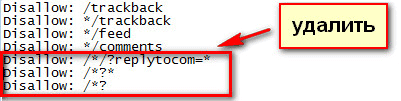
Затем необходимо будет добавить параметр replytocom в «Инструменты для веб-мастеров Google», как это сделать я написал выше в статье.
Настройки SEO плагина
Для предотвращения индексации страниц архивов, рубрик, меток, 404 страниц, страниц поиска, пагинации (постраничной навигации), в плагине All in One SEO Pack необходимо будет активировать пункты для добавления аргументов noindex, follow и noindex, nofollow (для постраничной навигации).
В плагине WordPress SEO by Yoast параметры индексирования для поисковых роботов будут выглядеть таким образом: noindex, follow.
Теперь, вам потребуется запастись терпением, и подождать когда Гугл удалит дублированные страницы из своего индекса. Если вы не хотите долго ждать, или если на вашем сайте осталось совсем немного дублированных страниц, то тогда вы можете ускорить их удаление.
Удаление дублей страниц вручную
Вы можете вручную добавить ссылки на дубли страниц в «Инструменты для веб-мастеров» для их удаления из индекса поисковой системы. Когда на моем сайте, в выдаче поисковой системы, осталось не так много дублированных страниц, я также вручную добавил найденные результаты, для более быстрого их удаления из индекса.
- На странице «Инструменты для веб-мастеров», в правой колонке «Панель инструментов сайта», сначала нажмите на кнопку «Индекс Google», а затем нажмите на кнопку «Удалить URL-адреса».
- Далее будет открыта страница «Удалить URL-адреса». На этой странице нужно будет нажать на кнопку «Создать новый запрос на удаление».
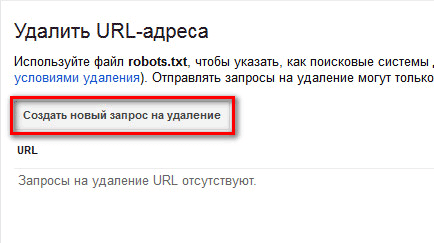
- Под кнопкой откроется поле, в которое следует вставить ссылку. После этого нужно будет нажать на кнопку «Продолжить».
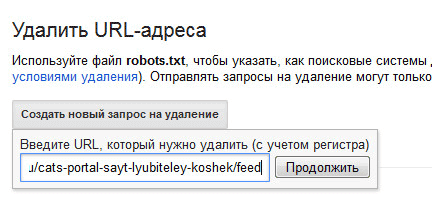
- Далее откроется новая страница, на которой будет отображен удаляемый URL. В пункте «Причина» выберите такой вариант: «Удалить страницу из результатов поиска и из кеша». Затем нажмите на кнопку «Отправить запрос».
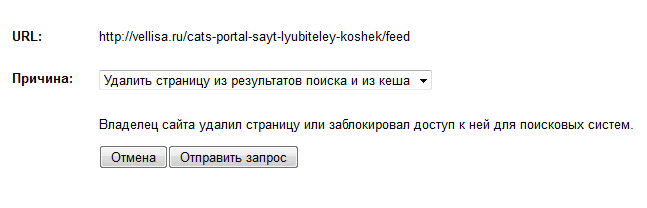
- На странице «Удалить URL-адреса» вы увидите добавленные ссылки, которые ждут очереди на удаление. Точно таким способом, вы можете добавить следующую ссылку для ее удаления из результатов поиска и из кеша поисковой системы Гугл.
Проблема существует, она может оказывать негативное влияние на продвижение сайта, поэтому администратору сайта нужно будет избавиться от дублей страниц для получения положительного результата.
Прошел месяц со дня опубликования этой статьи, теперь настало время дополнить публикацию новой информацией.
Как удаляются дубли на моем сайте
Сейчас я расскажу, как именно, в данный момент, осуществляется борьба с дублями страниц на моем сайте.
- Я удалил из файла robots.txt некоторые запрещающие директивы, для того, чтобы открыть доступ поисковым роботам к определенным директориям моего сайта.
- В плагине для СЕО оптимизации (AIOSP), мной были отмечены пункты для добавления мета тега роботс для соответствующих страниц сайта. Поисковый робот переходя на такую страницу увидит запрещающий метатег и не будет индексировать данную страницу.
Для этого был открыт доступ к определенным страницам в файле robots, для того, чтобы робот перешел на данную страницу, и увидел такие метатеги:
meta name="robots" content="noindex,nofollow" meta name="robots" content="noindex,follow"
Поэтому поисковый робот не будет индексировать страницу с такими метатегами. Ранее попавшие в индекс страницы, будут постепенно удалены из выдачи поисковых систем.
- Были добавлены параметры replytocom в панель веб-мастера Google.
- Мною был добавлен следующий код в файл htaccess:
RewriteCond %{QUERY_STRING} replytocom=
RewriteRule ^(.*)$ /$1? [R=301,L]
RewriteRule (.+)/feed /$1 [R=301,L]
RewriteRule (.+)/comment-page /$1 [R=301,L]
RewriteRule (.+)/trackback /$1 [R=301,L]
RewriteRule (.+)/comments /$1 [R=301,L]
RewriteRule (.+)/attachment /$1 [R=301,L]
RewriteCond %{QUERY_STRING} ^attachment_id= [NC]
RewriteRule (.*) $1? [R=301,L]В этот код вошли 301 редирект с replytocom, а также редиректы с другими параметрами, которые я взял с сайта Александра Борисова. Как я понял, автором редиректов для других параметров является известный блогер Александр Алаев (АлаичЪ).
Из файла robots.txt были удалены соответствующие директивы (feed, comments, trackback и т. п.) для параметров, которые были добавлены в файл htaccess.
После этого, поисковый робот переходя на дублированную страницу, которая имеет в URL адресе такие параметры, будет перенаправлен с помощью 301 редиректа на оригинальную страницу моего сайта.
- В файл functions.php был добавлен код для предотвращения появления новых дублей с replytocom, который нашел в интернете посетитель моего сайта, Антон Лапшин:
function replace_reply_to_com( $link ) {
return preg_replace( '/href='(.*(?|&)replytocom=(d+)#respond)/', 'href='#comment-$3', $link );}
add_filter( 'comment_reply_link', 'replace_reply_to_com' );Этот код нужно будет вставить в файл «Функции темы» (functions.php) перед закрывающим тегом ?>.
После вставки кода, при наведении курсора мыши на кнопку «Ответить» в комментариях, в ссылке, которая будет видна в левом нижнем углу окна браузера, теперь не будет появляться переменная replytocom. Следовательно, новые ссылки с этим параметром не будут добавляться в индекс поисковых систем.
Перед внесением изменений, не забудьте сделать резервную копию файла «Функции темы».
Все эти настройки работают, в основном, для поисковой системы Google. В Яндекс соотношение количества загруженных роботом страниц и страниц в поиске на моем сайте, на данный момент, оптимальное.
Еще один способ для борьбы с дублями страниц
Я нашел в интернете еще один способ для удаления дублей страниц из поисковой выдачи. С помощью кода на определенные страницы сайта будет добавлен мета тег роботс noindex, nofollow для запрещения индексации таких страниц.
Данный код вставляется в файл functions.php сразу за <?php для добавления на определенные страницы мета тега роботс noindex, nofollow. В этом коде запрещается индексация страниц с категориями, архивами, архивами по годам, по месяцам, по дням, по датам, по авторам, метками (тегами), таксономии произвольных типов записей, страницы с прикрепленными файлами, постраничной навигации (пагинации), фида, внутреннего поиска.
function meta_robots () {
if (is_archive() or is_category() or is_feed () or is_author() or is_date() or is_day() or is_month() or is_year() or is_tag() or is_tax() or is_attachment() or is_paged() or is_search())
{
echo "".'<meta name="robots" content="noindex,nofollow" />'."n";
}
}
add_action('wp_head', 'meta_robots');После добавления этого кода, в плагине для SEO оптимизации необходимо будет отключить добавление мета тега роботс к данным страницам. В плагине All in One SEO Pack — раздел «настройки индексирования (noindex)».
Затем необходимо будет убрать из файла роботс соответствующие запрещающие директивы.
Таким способом можно будет закрыть от индексации необходимые страницы. Только для избавления от дублей replytocom необходимо будет использовать один из методов, которые описаны в этой статье. Кроме использования редиректа и плагинов, также еще можно будет заключить ссылки с комментариев в тег span, для того, чтобы они не индексировались поисковыми системами.
После завершения настроек, вам нужно будет, время от времени, следить за процессом удаления дублей страниц с вашего сайта.
Выводы статьи
Вебмастеру следует обратить внимание на наличие дублей страниц сайта, и в случае их обнаружения, принять меры по их удалению из поисковой выдачи, потому что они негативно влияют на продвижение сайта. Из-за этого, сайт может попасть под санкции поисковых систем.
Привет, Василий! В файле Роботс у меня все вроде правильно прописано и Яндекс вроде не индексирует ненужные страницы. А вот Гугл индексирует все, и плевал он на файл Роботс) Попробовала задать параметры tag и feed у Гугла в вебмастерской. Параметр replytocom там уже был. Правда там стояло «На усмотрение робота Гугла». Я изменила как ты написал. Посмотрим что будет.
Постепенно количество дублей будет уменьшаться. Яндекс придерживается директив в файле robots, а Google не очень.
Юля, можешь сделать как я делал у себя. Нужно будет добавить код в файл htaccess, в панели веб-мастера ты уже все сделала. Из файла Robots.txt удали директивы со знаком вопроса. Затем нужно будет подождать некоторое время. Если дублей будет уже не так много, то можно будет ускорить процесс их удаления вручную.
Disallow: /*?*
Disallow: /?feed=
Disallow: /?s=
Disallow: /*/?replytocom=*
У меня feed тоже со знаком вопроса. Его тоже удалить?
Удали все эти директивы. Feed сделай как у меня:
Disallow: /feed
Disallow: */feed
Disallow: */*/feed/*/
Хотя разницы между этими пунктами, скорее всего никакой нет. Первая команда закрывает все то, что указано в двух других директивах.
Василий я сделала запрос на удаление дубля страницы, и меня заинтересовало, а когда состоится удаление ее, ведь в статусе написано ожидание удаления?
Ответ на этот вопрос знает только Google. У меня, после добавления запроса на удаления URL, уже на следующий день этих адресов уже не было в результатах поисковой выдачи.
Василий, здравствуйте! Сегодня в комментариях Александра Борисова прочитала, что он не советует вручную удалять дубли страниц через вебмастер, пишет, иначе весь сайт пропадет в выдаче. Я удалила некоторые дубли, как вы посоветовали. И вроде все на месте. Может я чего не так поняла правда.
Софья, я удалял дубли страниц вручную. Как видите с моим сайтом ничего страшного не произошло.
По моему мнению, если удалять дублированные страницы в разумных количествах, то никаких негативных последствий не будет.
А иначе, затем тогда бы Google добавлял такой инструмент для пользователей?
Привет, Василий! Спасибо за очень полезную статью! Я раньше уже боролась с дублями страниц, когда в бане Яндекса была, сейчас решила еще раз проверить. Яндекс ничего не показывает, это меня порадовало, а вот с Гуглом не все так красиво.
Проверила роботс.тхт, у меня там стоит Allow: *?replytocom! Я помню, что меняла disallow на allow давно, по чьему-то совету (убей не помню, по чьему!) Но, судя по всему, работает правильно! В Яндексе ничего, а Гугле всего один дубль с replytocom, там и ошибку показывает всего на один комментарий к одной статье. Пока не поняла, как исправить. Попробовать удалить вручную?
У меня больше дублей с параметром feed, добавила его в список параметров.
Роботс пока трогать не буду.
Галина, привет! В директиве Allow: *?replytocom не вижу смысла. Для чего призывать специально индексировать такие ссылки? Робот Гугла и так их с удовольствием индексирует.
Ссылки можно удалить вручную, что с replytocom, что с feed.
Галка, мы это ставили, когда в Твоем старте учились, я точно помню — недавно даже урок нашла. Я на днях убрала это Allow: *?replytocom , а вот что дальше делать — хоть убей меня, не знаю.
Да, нет. Мой Роботс из Твоего старта (бесплатный курс). Там такой директивы точно не было. Я его немного модифицировал, но основа — тот самый файл.
Вначале там вообще вообще не было строчки про replytocom, потом я её сама добавила с Disallow только (вычитала где-то), а позже кто-то настоял поменять на allow, возможно на платном курсе в Твоем старте.
Галина, а сейчас как там на новом хостинге, все уже нормализовалось?
Василий, если при добавлении в Гугл параметра replytocom надо удалить из robots.txt директивы с ?, то логично, что при добавлении параметра feed надо удалить директивы с feed? Или не надо?
Олег, у меня с feed директивы без вопросов. Я их не удалял.
Директивы с вопросами удалялись из файла robots.txt, потому что в файл htaccess был добавлен соответствующий код.
Используя этот код, по 301 редиректу, поисковые роботы переходят с URL содержащий replytocom на основную страницу, которую они индексируют, не индексируя ссылку с вопросами. Поэтому директивы содержащие вопрос были убраны из файла robots.txt. Такое решение этой проблемы пришло к нам из зарубежного интернета.
Олег, я вот подумал на эту тему. Наверное, с feed нужно будет поступать так.
После добавления параметра feed в панель для веб-мастеров Гугла, нужно будет удалить директивы с feed из файла robots.txt для того, чтобы поисковый робот мог по ним переходить и стал постепенно удалять такие страницы из индекса.
Если оставить feed в файле robots, то новые страницы не будут добавляться, а которые уже есть в индексе не будут удаляться из-за запрета в файле robots.
После того, как все ссылки с feed будут удалены из индекса Google, можно будет опять добавить в файл robots директивы с feed. Будет как-бы двойная защита.
Большинство файлов robots.txt имеют два раздела, один раздел — конкретно для Яндекса. В разделе для Яндекса директивы с feed нужно будет оставить, чтобы Яндекс не индексировал такие страницы.
Василий, мегапост. На всех других проектах настроил параметры url для Гугла. Спасибо. Кстати, Гугл иногда не индексирует «сопли» несмотря на то, что ничего не закрывается. Почему — так и не понял.
Дмитрий, спасибо за оценку. С Гуглом сложно, не поймешь, как и почему он поступает именно так, а не иначе. Это с Яндексом все просто: закрыл, что надо в файле robots и спи спокойно.
Да, вроде бы нормализовалось, спасибо! Мне Лариса почистила логи, кеширование настроила, превышение лимита нагрузки и сейчас бывает, думаю, в следствии атак, но уже не так критично. Во всяком случае, за превышение нагрузки меня больше не блокируют.
А вообще, у них там не забалуешь, то за нагрузку заблокировали, а потом, за недостаток средств, на раз-два-три! Я заплатила за месяц, как обычно делала на Спринтхосте, а на Макхосте, оказывается существует система авансовых платежей, не читала договор, сама виновата. Так вот, списали средства за следующий месяц, а их не хватило и за -36 рублей, заблокировали сайт без предупреждения! Меня, как назло, опять дома не было. Еще раз сайт просел. В общем, все как на вулкане…
Да, серьезный хостинг.
Кстати, возможно спад и рост посещаемости в гугле у вас был связан вовсе не с дублями)
Спад посещаемости был связан не только с этим. А вот рост посещаемости в Google связан именно с этим. Других причин просто нет.
Похоже, понял почему так происходит — тема для отдельного исследования) Например, я ничего не делал, на своем блоге, но соплей нет. Только сегодня понял.
Значит, на сайте наверняка, что-то такое есть, что не дает Гуглу добавлять дубли в индекс.
Ни в коем случае не удаляйте URL адреса через инструмент удаления в URL в Google. Это проверено. Через несколько недель у вас ухудшатся позиции, а потом сайт вовсе вылетит из выдачи!
А почему у меня не вылетел? Удаляются ведь дубли страниц.
Александр не неси ерунду, уже 3 года удаляю через инструмент удаления, и сайту от этого,становиться только легче. Проверенно временем.
Значит вам повезло.
Спасибо, Василий за статью! «replytocom» у меня нет, а вот feed присутствуют. Создал правило в вебмастере гугла, буду убирать из robot.txt «Disallow: */feed». А «Allow: *?replytocom» — присутствует точно из «Твоего старта». То ли Гаврилов, то ли Ходченков сказали, что обязательно, да и фрилансер сказал, что это нужно. Вот бы мне еще 404 из яшки удалить! Посылал запросы на удаление, но все равно висят уже долго.
Александр, а вы в файле robots.txt, в части для Яндекса оставьте «Disallow: */feed», чтобы он не индексировал такие ссылки. Потом проверьте, вставив ссылку содержащую feed в панелях для веб-мастеров Яндекса и Google, чтобы узнать, запрещаются или разрешаются к индексации страницы содержащие feed, конкретно в каждом поисковике.
Если таких страниц у вас не так много, то можете удалить их вручную, не удаляя из файла robots.txt эти директивы.
По поводу «Allow: *?replytocom» могу сказать только, что если не будет в файле robots.txt директивы «Disallow: *?replytocom», то поисковые роботы итак будут индексировать такие страницы без всяких «Allow». Если такая команда ставилась намеренно, то значит на сайте что-то еще делалось для запрещения индексации дублей. Другие блогеры просто скопировали этот файл со всеми командами на свои сайты.
Яшка feed не видит, в роботе я их оставил. А из гугла feed в роботе пока убрал и на удаление сделал запрос (штук 30). «Allow: *?replytocom» в роботе — что бы если появляются, то сразу удалялись по правилу в вебмастере.
Проверяйте потом в веб-мастере время от времени, остались еще дублированные страницы или нет. Если даже на посещаемость удаление дублей никак не повлияет, то хотя бы дубли не будут забирать вес у основной страницы, что уже хорошо.
И еще вопрос: «Disallow: /?pass=1» в роботе, это что такое? Нужно удалять?
Александр, а у вас есть вообще на сайте страницы содержащие этот элемент? Предположу, что это связано с каким-то паролем, непонятно от чего.
Сам не знаю. Есть на Wppage продающие страницы.
Тогда возможно, так закрываются эти страницы.
Впрочем гугл не видит site:muzrestor.ru ?pass=1
Тогда и переживать не стоит по поводу этой директивы.
Спасибо за ценную информацию. Вот только, как 404 из яшки удалить!
Добавляя в панель вебмастера такие страницы вручную. Правда, Яндекс не быстро удаляет добавленные страницы.
Скажите, Василий, у меня очень много дублей с параметром Tag, хотя индексация меток запрещена в Robots.txt Нужно ли прописать этот параметр в вебмастер Google?
Евгения пропишите, хуже точно не будет. Я у себя добавил этот параметр в панель для веб-мастера Google.
А если после написания статьи помещаешь ее в две рубрики — это тоже будет дублирование текстов?
Бурул, вам сейчас, может быть, лучше будет избавиться от рубрик в URL. Ссылка на статью будет иметь такой вид: название сайта/название статьи. В этом случае вы сможете без проблем менять рубрики, удалять статьи из рубрик, добавлять статьи в разные рубрики не изменяя ссылку на статью.
Статья заново будет проиндексирована без рубрики в адресе URL, поэтому дублем считаться не будет.
У меня раньше у самого была такая ситуация. Раньше, на моем сайте было мало рубрик. Когда мне нужно было переместить статьи в новые рубрики, то в адресе страницы оставалась старая рубрика, что создавало проблемы. В итоге, я удалил рубрики из ссылок на статьи своего сайта.
Василий, я сама хочу избавиться от названий рубрик в URL, потому что получаются очень длинные ссылки. Как это сделать? Настраивала ЧПУ по советам веб-мастеров. В настройках прописала /%category%/%postname%.html. Я думаю, нужно удалить слово /%category%/ и тогда в URL не будет прописываться рубрика?
Да, правильно, оттуда нужно будет удалить /%category%/. Для того, чтобы не лишится трафика с поисковых систем, пока заново не будут проиндексированы новые адреса, установите плагин WP No Category Base или WP No Category Base — WPML compatible. Просто активируйте его, и забудьте о плагине. С его помощью переходы по старым ссылкам будут перенаправляться на новые ссылки без категорий.
Василий, я установила плагин WordPress Thread Comment, отключила древовидные комментарии в настройках. Нужно ли в таком случае править файл Robots.txt и добавлять параметр replytocom в Инструменты для веб-мастеров?
А у вас в файле robots нет директивы с replytocom. Такую директиву добавлять туда не нужно. Можете еще, если хотите, также добавить параметр в панель управления Гугла.
После установки плагина, новые дубли с replytocom появляться у вас уже не будут.
Спасибо, Василий, за классную информацию. До этого я уже добавляла replytocom в вебмастере Гугла месяца 2 назад. Зашла сейчас посмотреть: в индексе Гугла аж 10 страниц комментов. Значит, без редиректа этот метод не срабатывает. Все сделала по твоему описанию, теперь буду ждать, но уже сейчас уверена (судя по твоим исследованиям), что результат будет 100%!
Новые страницы с replytocom добавляться уже не будут. Старые страницы удаляются Гуглом не так быстро, как хотелось. Когда таких страниц у меня осталось не так много, я удалил дубли вручную, через панель веб-мастера.
Потом, время от времени, нужно будет проверять сайт на наличие дублированных страниц. Иногда, могут появиться несколько дублей откуда-то из «недр» сайта. Их можно будет удалить вручную.
А мне непонятна такая ситуация: в поисковой выдаче у меня ничего лишнего нет (на одном сайте только несколько постов с редиректом скрыты из-за ограничения в robots.txt). А если смотреть проиндексированные урлы, то их в 15 раз больше. Вот с этим как быть? И надо ли с этим что-то делать?
Нина, а что именно вы называете проиндексированные урлы?
У меня, например, на данный момент, в панели веб-мастеров Google: отправлено — 197, проиндексировано — 196, в Яндексе — в индексе 196. Если смотреть в SEO программах, то там совсем другие данные.
В Site-Auditor показывает в Яндексе — 368, в в Google — 1590. У меня больше доверия вызывают показатели самих поисковых систем.
Я думаю, что главное, чтобы дублированных страниц не было в результатах поисковой выдачи, как в основном индексе, так и в дополнительном.
Я имею в виду, что на одном сайте в поисковой выдаче 90 записей (это вместе с теми, что были скрыты), а в панели вебмастеров гугла написано, что проиндексировано всего 1332. На другом: в поисковой выдаче 154 (скрытых нет), а в вебмастере 658. Отсюда вопрос: откуда взялись лишние, как их найти и надо ли их искать?
Различие существенное, особенно в первом случае. В результатах выдачи других страниц нет, это неплохо. А вот, что еще Гугл индексирует кроме статей, непонятно. Может изображения? Хотя не уверен в этом.
У меня одна страница на сайте генерировала дубли. Я в вебмастере Яндекса заметил, что у меня в структуре сайта более 4000 таких страниц. Каким-то образом, такие страницы воспроизводились сами по себе. Я закрыл эту страницу в файле robots, изменил URL. Примерно через месяц, Яндекс удалил все эти страницы. Сейчас все нормально. Может у вас что-то похожее?
Василий, древовидные комментарии вы оставили?
Если не добавлять код в htaccess, а только провести манипуляции в ПУ Вебмастера, из robots надо удалять запрещающие директивы для replytocom?
Сергей, да я оставил древовидные комментарии.
Если не добавлять код в файл htaccess, то в файле robots.txt удалять запрещающие директивы для replytocom не нужно.
Т.е. в настоящее время у вас включен редирект в htaccess и указано правило для replytocom в ПУ вебмастера Google, верно?
Да, верно. В файле robots.txt у меня сейчас вообще нет директив с вопросительными знаками.
Я при проверке индексации сайта тоже не обнаружил проиндексированных статей с переменной replytocom, поэтому не включил этот параметр в robots.txt, но вот у меня некоторые сомнения есть по поводу индексации рубрик. Я заметил, что часто на сайт заходят посетители по запросам названия рубрик, и вот думаю, нужно ли закрывать рубрики от индексации? Хотя их проиндексировано не очень много, но они есть.
Рахим, тогда не закрывайте рубрики от индексации. Для того, чтобы по названиям рубрикам заходили посетители, у рубрик должны быть оригинальные названия. Если, на моем на сайте есть рубрика «программы», то понятно, что при таком названии рубрики, ждать посетителей мне придется долго. А если бы название рубрики было, например, таким «необычные программы» или «удивительные программы», то в этом случае, названия рубрик привлекали бы поисковый трафик.
Статья просто шикарная, но я окончательно запуталась)
Итак, проверяю свой сайт — дублей от реплитуком нет.
А в файле robots.txt имеется директива Disallow: /*/?replytocom=*
Нужно ли мне что-то менять, удалять и как-то с этим бороться или расценивать как все в порядке?
Но есть другие дубли на сайте — рубрики… Что с этим делать?
Галина, с этой директивой (replytocom), можно поступить двумя способами: оставить все, как есть, если у вас все нормально, или удалить этот параметр от греха подальше.
Вообще наличие в файле robots директивы с replytocom может грозить опасностью, в том плане, что роботам запрещено переходить по ссылкам с этим параметрам. Поэтому они не будут удалять такие ссылки из индекса поисковых систем, если они там появятся.
У меня в файле роботс нет директив с вопросами, я их удалил. У себя на сайте я использовал 301 редирект в файле htaccess. После удаления дублей, поисковый трафик с Гугла повысился в два раза. Собственно поэтому я и написал эту незапланированную статью.
Если у вас с поисковым трафиком все нормально, то тогда может быть, вам ничего и не нужно менять. Если трафик с Google значительно меньше, чем с Яндекса (в 4 и более раз), то тогда, наверное, будет лучше провести изменения.
Галина, под рубриками вы имеете ввиду — category. Таких страниц у вас совсем мало. Увидел у вас еще URL с такого типа составляющей — 2014/06/, перед названием статьи. Мне не совсем понятно, что это такое. Это тоже считается на вашем сайте рубриками, или это обязательная составляющая часть адреса статьи?
У вас в «соплях» очень много страниц с page.php, хотя в robots.txt все закрыто — Disallow: /*.php
Могу посоветовать еще закрыть в панели веб-мастера Гугла параметр feed. А все ссылки с дополнительного индекса Google постепенно удалите вручную. Например, сегодня удалите 20 ссылок, через пару дней еще 20, и так далее, наблюдая за изменениями. Ждать пока поисковик их удалит можно очень долго. У себя на сайте, я немного «помог» Google удалить дубли из результатов поисковой выдачи.
Спасибо огромное! Не ожидала получить такой развернутый ответ — прямо персональная консультация! Очень приятно.
Относительно Ваших замечаний — попробую переварить все это и что-то поменять… У меня с гугла посещаемость лучше, чем с Яндекса, но не нравится в целом динамика роста с поисковиков… Посты пишу каждый день, а с поисковиков в среднем 400 уников/сутки. Хочется больше конечно.
Вы очень наблюдательный, сама не знаю откуда эта дата в урле? 2014/06… Но понимаю так что уже ничего трогать нельзя?
И по поводу replytocom… Пока ссылки там не появились я так понимаю, что можно не беспокоиться? Или все же лучше предвосхитить и настроить редирект как у Вас? Просто очень не хочется в файлы блога лезть, я не особо в этом разбираюсь…
Василий, добрый день! Я снова вернулась к этой теме. В прошлый раз так ничего и не сделала, а сегодня еще и у Саши Борисова статью на эту тему увидела. Поняла, что это уже не просто так…
У меня такой вопрос, стоит ли внедрить все перечисленные способы борьбы с «соплями» или достаточно одного-двух? Если изменить роботс.тхт, то нужно ли делать редирект? Плагин я тоже ставить не хочу.
Галина, лучше сделайте редирект, хуже точно не будет. Я у себя сделал так — установил код в htaccess, удалил директивы со знаком вопроса из файла robots.txt, а также добавил в инструменты для вебмастера Google запрет на индексацию replytocom.
Борисов считает, что жесткий запрет на индексацию не нужно делать, а по усмотрению робота, я у себя сделал иначе — никакие URL.
Вариантов решения проблемы много, можно использовать плагины. Делайте так, как вам удобнее.
Редирект сделала. В инструментах вебмастера запрет на индексацию replytocom у меня уже был, но на усмотрение робота, я исправила, как у Вас на «никакие». Еще добавила параметры feed и trackback, поскольку у меня есть такие дубли.
А вот что касается роботс.тхт, как я уже писала, у меня прописано вот так:
Disallow: /*?*
Disallow: /?s=
Allow: *?replytocom
Я помню, что Вы написали, что не видите смысла в директории Allow, но тем не менее, Гугл не показывает дублей с replytocom, значит, это работает. Вот потому и не хочу в него влезать. Хотя была мысль, передрать у Саши Борисова его роботс.
Еще нашла другие странные дубли, например:
kak-ispech-tort-napoleon-111-Галина
img_9037
Гарниры(1)-Галина
И тому подобное. Много дублей (если это дубли с img, на изображения.
Не знаете, как от них избавляться?
У Борисова не нужно копировать robots.txt. Там очень много лишних записей, у нас на сайтах просто нет таких разделов. У него многие разделы созданы для бизнеса. Хотя я на некоторых сайтах видел этот файл, скопированный у него.
После добавления 301 редиректа, записи с вопросами в файле robots уже не нужны, их нужно будет удалить. Работу редиректа нужно будет проверить. К урлу любой своей статьи добавьте, что-то типа ?replytocom=1254, а потом нажмите на «Enter». Должна будет открыться страница сайта, в адресе страницы без переменной replytocom.
Конечно, такие окончания ссылок не совсем понятные, откуда они берутся. Галина, попробуйте их удалить вручную. Не все сразу, а постепенно, по частям.
У Борисова очень коротенький роботс, только сегодня его смотрела.
Значит, совсем недавно он его заменил. Нужно будет посмотреть. Я не так давно видел его роботс, простыня была очень длинная.
Здравствуйте Василий, я так сделала и у меня открылась страница 404, вместе с подставленным мною в браузерной строке replytocom=125. Видимо что-то не так поняла.
Татьяна, возможно, вы что-то не так сделали. Если вставить код из статьи в файл functions.php, то новые страницы с replytocom уже не будут появляться. Для старых ссылок добавляется код с параметром replytocom в файл htaccess.
Именно так это работает в данный момент, на моем сайте. В случае с replytocom этот метод точно работает. По другим параметрам я пока наблюдаю за работой кодов.
Вообще я начал борьбу с дублями в начале декабря 2013 года. Тогда в веб-мастере Google (в статусе индексирования) у меня было проиндексировано 7139 страниц, а сейчас, в конце июля 2014 года, осталось 977 страниц. Вот так постепенно убираются из индекса Гугла ненужные страницы.
Да, редирект я сразу проверила, работает!
Ну, если буду убирать строчки с вопросами в роботсе, может тогда и строчку Allow replytocom удалить… Это я размышляю. Как мне не хочется влезать в роботс!
Василий, когда посмотрите Сашин роботс, может отпишитесь здесь? Если все нормально, может скопирую все-таки.
Галина, лично от себя добавлю: Allow replytocom удаляйте смело, Сашин robots брать не советую.
Галина все верно, не берите мой роботс, возьмите Сергея, у него нормальный. 56 000 дублей replytocom, там же и page, feed, tag и т.д.
Я сейчас набрал в поисковике правильный роботс для wordpress и понимаю как похоронили «умники» блогосферу.
А у Вас 164,000 дублей replytocom и что? Будем числом дублей мериться или здравой логикой и техническими знаниями?
Сергей сначала перед тем как писать, почитайте мою статью.
Там и логика и технические знания проверенные на практике и т.д. Дублей у меня было 300 000
Весь вопрос в том, Александр, с какой целью была написана Ваша «знаменитая» статья и как она «по счастливому стечению обстоятельств» вышла ровно через неделю после анонса Вашего нового курса с версией 3.0 ))
Ну и конечно Ваши частые посылы в комментариях к покупке этого курса нельзя не заметить.
Я в совпадения давно не верю, а в инфобизнесе вижу изнанку всех процессов — есть опыт.
Присоединяюсь к Сергею, файл Александра не нужно копировать.
Если на него даже просто посмотреть, то видно, что он очень уж лаконичный.
Первая часть файла относится к роботу AdSense. Это вообще нам не нужно, у него какие-то свои соображения по этому поводу.
На моем сайте дополнительно закрыты еще такие директории:
Disallow: /cgi-bin
Disallow: /wp-admin
Думаю, что это не будет лишним. Можно закрыть файлы wp-login.php, wp-register.php и т.п. Такие файлы также можно закрыть одной строчкой:
Disallow: /*.php
Остальные директивы делают на усмотрение пользователя. Например, у меня раньше в индексе были страницы пагинации, я добавил запрещение page, и Яндекс удалил лишние страницы из индекса.
На моем сайте нет ompin, поэтому смысла копировать такую директиву нет.
Яндекс рекомендует создавать специальный раздел для своего робота. Хотя, конечно, поисковики рано или поздно проиндексируют любой сайт, даже если на нем нет файла роботс.
Я хочу у себя удалить из файла все записи с feed, так как я добавил в инструменты вебмастера запрещение на индексацию этого параметра. А если этот параметр закрыт в robots, то роботы не переходят по ссылкам и не удалят дубли содержащие feed. Посмотрю как будут дальше идти дела.
Сергей, Василий, спасибо большое! Обязательно прислушаюсь! Поняла, что нужно сидеть и удалять вручную все записи с feed. А как насчет того, что Саша Борисов написал, ничего не удалять вручную?
Сейчас проверила еще раз редирект, что-то меня смутило, replytocom и номер ответа исчезает, но #respond присутствует в URL. Это нормально или что-то не так?
Василий, а пропишите, пожалуйста строчку запрета c page, я тоже себе добавлю, у меня много такого хлама. А вот img нужно запрещать, они же тоже дубли дают?
Галина, у Борисова свой опыт, у меня свой. Я удаляю, если нужно, ссылки вручную. Например, у меня попадались ссылки с рубрикой в урле. А рубрик в урле на сайте нет уже полгода. Если по такой ссылке перейти, то с помощью редиректа будет открыта страница уже без рубрики в URL. А зачем мне такие ссылки держать и ждать неизвестно сколько, когда Гугл их удалит? Я их удалил вручную. Думаю, что следует придерживаться такого правила: удалять все постепенно, по немного.
Окончание #respond — это нормально.
Страницы пагинации можно закрыть так:
Disallow: /page/
Яндекс удалит такие страницы после очередного апдейта индексации, а Гугл даже не подумает это сделать. Я их удалил вручную, их было не так уж и много.
Про img не знаю. Галина, а что у вас открывается, если перейти по такой ссылке?
Спасибо за подсказку! Тоже добавлю в роботс.
А по ссылкам с img открываются картинки. Я не у всех картинок названия меняю и многие из них так и остаются как были со своими номерами, это же фотографии. Я вначале меняла названия картинок, чтобы с ключевыми словами были, оптимизировала в общем. Потом заметила, что даже если только название поменять, не говоря уже про водяной знак, это сильно утяжеляет картинку, вот и перестала. Думаете, нужно теперь все картинки переименовать? О, ужас!
Пока картинки не трогайте. У изображений, наверное такой URL — «…/wp-content/uploads/…» Если порассуждать, то такая ссылка не является дублем какой-либо статьи. У нее же совсем другой урл. Тогда логично будет предположить, что такие ссылки дублями не являются. Правильное это предположение или нет, не знаю.
У Борисова (опять мы его упоминаем) в robots даже вставлен специальный код для индексации картинок:
User-agent: Googlebot-Image
Allow: /wp-content/uploads/
Василий Disallow: /page/ это наоборот хуже. Я написал про это в статье. Неужели никто не может понять суть.
Я все по полочкам разложил. Запретили в robots гугл съел. Открыли, поставили редирект или метатег, то все отлично.
У вас куча страниц page в выдаче.
Какая куча страниц с page в выдаче?
Александр, я заметил, что вы приводите цифру, которую дает Google, когда выдает результаты выдачи на запрос.
В большинстве случаев, эти цифры не имеют отношение к реальности.
Я ввожу site:vellisa.ru page, Google мне показывает: найдено примерно 359 ссылок.
Ладно, примем эту цифру. Хотя замечу, что такого количества ссылок с page не может быть даже теоретически, так как страниц пагинации на моем сайте всего лишь 33.
Проверяю все ссылки на 20 страницах выдачи. Есть только одна ссылка на страницу пагинации, все остальное — обычные статьи моего сайта.
Как я понял Google вырвал из выражения «Select Page: Where to?» шаблона моего сайта, слово «Page» и поэтому вывел все эти страницы в выдачу.
В скрытых результатах, есть еще 4 ссылки, из них только одна дубль, производная от первого дубля в основной выдачи.
Так и где эта куча дублей?
http://prntscr.com/42l6qhи так несколько страниц.Александр, я тогда проверил все страницы. Там было всего 2 дубля с page на 20 страницах.
С этого момента прошло всего два дня, ссылок с page стало уже 12 штук (а не 355 как можно подумать), уже на 21 странице.
Это говорит о том, что Google добавляет эти страницы в дополнительный индекс. Выходит, что придется опять добавить запрещение индексации page в файл robots. В ту часть файла, что предназначена для Яндекса я уже раньше вернул этот параметр.
Василий вы наверное тоже суть статьи не уловили. Ни чего не надо закрывать в Роботсе. На page надо ставить noindex. Посмотрите как у меня. Это я в предпоследней статье про дубли говорил как сделать.
Вставить мета тег вручную в page.php?
Удалять url в google не нужно! За это можно получить. Кому-то везет, а кого-то наказывают.
Вставка в page.php кода не поможет. Почитайте мою статью, я там спец.код давал для function.php чтобы page закрылись.
Я добавил тег noindex в плагине All in SEO Pack.
Василий, я, наверное, ошиблась и морочу Вам голову. Похоже, что это не дубли, а нормальный URL картинок. Извините.
Сижу, потихоньку удаляю урлы с параметром feed, а trackback тоже удалять?
Галина, trackback не нужны. Необходимо будет от них избавляться. По поводу trackback я почему-то зашел в админ-панель (раньше по моему там, что-то было про них в настройках), а потом перешел в настройки плагина All in One SEO Pack.
Там в разделе «Настройки индексирования», я увидел два новых параграфа. Раньше их не было и в статьях про этот плагин они никак не разобраны.
Я перевел с помощью переводчика объяснение. Это вроде бы закрытие в noindex, nofollow страниц пагинации, для предотвращения дублей.
Если я правильно понял перевод, то тогда в файл robots.txt не нужно будет добавлять директиву с page. Эти страницы от индексации закроет плагин, если активировать эти пункты.
Ну, там похоже нужно галочки во всех окошках ставить. Страницу поиска тоже, наверное, лучше не индексировать?
Да, конечно. Под поиском эти пункты и притаились.
Установил давно запрет в новых пунктах пагинации, но вот, если для тегов, например, запрет прописывается в коде в meta robots, то для пагинации ничего не меняется. Может еще не доработали толком.
Зашла к Вам с блога А.Борисова из комментариев, могу сказать Ваша статья оказалась еще более подробной чем у Александра! Интересно, как Вам двоим почти одновременно пришла мысль так удачно расправиться с дублями?!
Александр стал об этом думать даже раньше, когда у него сильно просел трафик с Гугла. Я даже наблюдал за ним на других сайтах, как он искал ответы на этот вопрос.
Я вплотную занялся этим вопросом полгода назад, после смены шаблона. На сайте нужно было наводить порядок. У меня тоже просел трафик с Гугла, но не так катастрофически как у Борисова.
Мои манипуляции пронесли хороший результат, трафик с Google вырос в два раза. Поэтому, я не удержался и написал об этом статью, хотя это и не моя основная тематика.
Здравствуйте, Василий, зашла на Ваш сайт из поисковой системы, про удаление дублей и хотела узнать, впервые встретила статью, где все изложено так понятно и простым языком, что даже мне, чайнику, практически все ясно. Я прочла все комментарии, они ведь тоже помогают, я проверила свой сайт, обнаружила дубли по параметрам tag, pade, feed, category, replytocom отсутствует. Я правильно поняла, что достаточно сделать ограничение по этим параметрам в Google webmaster, чтобы дубли постепенно выпали их индекса? Или тоже нужны манипуляции с robots.txt?
Здравствуйте Людмила! Посмотрел ваш сайт. Для того, чтобы гугл выкинул из своего «сопливого» индекса вышеуказанные вами страницы, вам нужно в файле robots.txt в разделе User-agent: * удалить следующие строки:
Disallow: /tag
Disallow: /category
Disallow: /archive
И на всякий случай занесите эти параметры в гугл вебмастер с настройкой — на усмотрение GoogleBot.
Для Яндекса не чего не трогайте, так как он пока нормально относится к запретам указанным в файле robots.txt
Еще на счет параметра Feed. На многих заграничных сайтах по СЕО рекомендуют не запрещать. Так как благодаря ему роботы быстрее индексируют статьи. У себя его из роботса удалил.
Подождем, что ответит вам Василий.
Антон, спасибо, что откликнулись, буду исправлять
Людмила, по feed можно сделать таким образом: удалить этот параметр из файла роботс, а в панели вебмастера запретить их индексацию. Постепенно такие страницы должны будут удалиться из поисковой выдачи.
По другими параметрами я пока не могу дать однозначного совета.
Также учитывайте, что мы тут не какие-то супер специалисты, а обычные пользователи, которых необходимость заставила заняться этой проблемой. Мы делимся своими мнениями, находим в процессе обсуждения какие-то новые решения. Возможно, не всегда наши советы бывают правильными.
Спасибо, Василий, это и ценно, что Вы делитесь собственным опытом.
Здравствуйте Василий! Тоже начал изучать данную проблему и перечитал ветки комментариев и у Вас и у Веб-Кошки:
В комментариях Веб-Кошка сказала что редирект 301 не дал нужного результата.
Проверил сам, что редирект отключен и у Вас и у нее. Но на открывающихся страницах с ?replytocom стоит строчка тега
Как вы ее туда вставили?
Как же в итоге победили replytocom? Простым удалением из Вебмастер Гугл и удалением из роботса, чтобы переходил и видел строчку:
У вас же нет теперь соплей в выдаче гугла. Или же Борисов помог?
Антон, я ничего не отключал, это проделки плагина безопасности. Из-за этого плагина мне приходится иногда удалять с хостинга, а потом снова загружать туда файл htaccess. Вчера, я также заметил отсутствие 301 редиректа на своем сайте. Я вставил в файл htaccess нужный код, все опять заработало как надо. Сегодня вот опять, все пропало, в файле осталось только содержимое стандартного кода. Завтра еще раз посмотрю, как будут идти дела.
Моя статья была опубликована раньше, чем его статья на подобную тему. Поэтому можно понять, что Борисов мне ничем не помогал. Да, он там в обсуждении предлагал поэкспериментировать, но дальнейшего развития эта тема не имела.
Спасибо за ответ! Сегодня весь день ковырялся как убрать с кнопки «Ответить» ссылку на replytocom и кажется нашел. Позвольте поделится.
Данная функция отключает образования новых дублей страниц при включенных древовидных комментариев на WordPress.
Вставить в конец файла function.php вашей темы, перед закрывающим тегом >
function replace_reply_to_com( $link ) { return preg_replace( '/href=\'(.*(\?|&)replytocom=(\d+)#respond)/', 'href=\'#comment-$3', $link ); } add_filter( 'comment_reply_link', 'replace_reply_to_com' );Антон, очень хорошо, что вы поделились полезной информацией.
Все работает. С помощью вашего редиректа перенаправляем существующие страницы, а с помощью кода в function.php предотвращаем появление новых страниц с replytocom
Привет, Василий. Долгое время не общался с тобой, однако, рад возможности дать комментарий к твоей статье. Мануал очень полезный и информативный, ты даже немного опередил меня, сам только-только хотел написать о проблеме replaytocom и опыте моих изысканий, но ты меня опередил.
Единственное, я бы не советовал сейчас брать на вооружение плагин WordPress Thread Comment, поскольку он давно не обновлялся, о чем висит соответствующее предупреждение на официальном сайте WordPress.org. Поэтому его использование, во-первых, может не дать эффективного результата, особенно для последней версии движка, а во-вторых, несет угрозу безопасности.
Привет, Игорь. Я также там видел, что плагин давно не обновлялся. Есть еще другие плагины для борьбы с дублями, о которых я не упоминал в этой статье.
Сегодня прочитал, что есть еще один вариант решения проблемы — добавление кода php с регулярными выражениями. Из-за недостатка знаний, я не могу проверить на работоспособность такой вариант. Может ты посмотришь?
Смотрю, вы поставили код.
Да, поставил, все работает. Антон, спасибо за код.
А плагин, действительно, изменяет файл htaccess. Утром было все нормально, а потом заметил, что сайт стал медленнее открываться. Проверил, плагин опять поменял код на стандартный. Спрошу у знающих людей, как справится с этой ситуацией.
Как вы точно подметили это ваш плагин безопасности мудрит. Он видит что код htaccess поменялся — значит кто специально его подменил. Вот он и чистый htaccess восстанавливает.
Вы даже Борисова опередили с этой темой…
Я же не знал, что Борисов про это тоже скоро напишет.
Василий, доброе утро! Сейчас на новом сайте нашла среди скрытых страниц в поиске Гугла много адресов такого типа:
Это адреса изображений. Интересно, нужно ли удалять такие адреса? Часть адресов ведет на удаленные картинки, понятно, что эти можно удалить, а вот ссылки на существующие картинки, что с ними? Являются ли они дублями? Ведь не должно быть ссылок на отдельные картинки?
Совсем я уже запуталась с этими дублями…
Считается, что это дубли. У меня вообще не было в роботсе записи с attachment, хотя картинок тоже очень много, они почему-то не добавлялись в индекс.
Галина, сделайте редиректом, как написано во второй статье Борисова. Только удалите из роботса директивы, чтобы редирект работал.
В иерархии команды в robots.txt стоят для поисковых роботов выше, чем другие (редиректы, метатег robots), поэтому, чтобы другие команды работали, следует удалить соответствующую директиву из robots, чтобы поисковый робот выполнял соответствующие команды.
Сейчас почитала вторую статью, проверила оба сайта по всем категориям, replytocom у меня, действительно, нет, некоторые другие есть, но не очень много. Буду сейчас переделывать, согласно инструкциям. Спасибо, что подсказали, я не знала, что вторая статья вышла.
Василий, добрый день! Почитала я статьи про дубли у Вас, у Борисова. Еще к Максиму Войтику зашла и в конец запуталась. Этот вопрос меня волнует не первый день и неделю. Начала интересоваться еще раньше. У меня с середины января стоит платная тема. Мне сказали, что платные темы не должны создавать никаких дублей. Но дубли есть всех видов. Одних меньше, других больше. Все от старой темы. Я просто вижу, что статьи старые. Но, некоторые статьи с replytocom (из поиска) открываются как основная страница, без дубля. А есть, как и положено в таком случае, с приставкой replytocom и номером. Вроде они убывают. Следить стала в последнюю неделю. Изменения сделала только в файле роботс. Больше ничего не трогала. И теперь не знаю, что делать. Действовать дальше, т.е. прописывать в Гугле, или не нужно. В файле htaccess мне вообще все прописывали на хостинге ребята. И еще проблема, у меня раньше поддомен был на сайте. Он еще свою «копейку» внес. Сейчас я его удалила, вернее перенесла на отдельный домен. Месяц прошел, но дубли с него остались. Подскажите, что мне делать, ждать или все же внести изменения? Спасибо.
Дубли с replytocom создает сам WordPress, тема тут не причем. Просто в некоторые темы вставляют соответствующий код, чтобы не создавались дублированные страницы. Конкретно, в вашу тему такие коды не были вставлены. Я думаю, что в большинстве платных тем, такая же картина, как у вас.
Любовь, добавьте 301 редирект в файл htaccess, а в файл functions.php код, который нашел Антон (я его добавил в статью). После этого дубли с replytocom появляться уже не будут, а старые будут постепенно удаляться из выдачи.
Дубли с поддомена удалите вручную. Как я понял, по старому адресу его уже нет, а ссылки на него есть.
Василий, спасибо! Предпочла-таки редирект)
Ольга, правильно сделали. Это надежнее и безопаснее, чем самому создавать множество ссылок с 404 ошибкой. Думаю, что поисковики будут не в восторге от большого количества 404 ошибок на сайте, а с 301 редиректом они замечательно дружат.
Спасибо) А 301 редирект можно аналогично сделать для feed и page? И еще я обнаружила дубли такого вида (привет, Смарт): …/comment-subscriptions?srp=3148&sra=s
Их бы тоже того…
Да, можно. У Борисова во второй статье есть код для feed, page, attachment и т.д. Только не забудьте удалить соответствующие директивы из файла robots.
В вашей ссылке, наверное, что-то связанное с комментариями и подпиской. В том коде есть 301 редирект для comments, может быть это подойдет. Если таких ссылок совсем немного, то удалите их вручную.
Василий добрый день, благодарю за очень информативную и полезную статью. Буду ее использовать как шпаргалку при удалении дублей, в принципе все понятно. Один момент только, у меня ну очень слабое место это роботс, честно говоря ничего не понимаю там. Можно использовать ваш?
Пока читала комментарии нашла еще один ответ на свой вопрос, по поводу ЧПУ ссылок, хочу тоже убрать рубрики в URL, нужно прописать так %/%postname%.html ? И когда исчезнет необходимость использовать плагин WP No Category Base, после изменения ЧПУ, как это можно будет понять, смотреть url проиндексированных страниц?
Верхнюю часть (там где перечислены, если так выразиться, системные директории) моего файла robots вполне можно использовать. Далее необходимо будет смотреть на потребности для закрытия каких-либо директорий по конкретному сайту.
У меня были удалены некоторые запреты, так как для предотвращения появления новых дублей страниц, в файл htaccess были добавлены соответствующие редиректы.
В постоянных ссылках должно быть записано так — /%postname% или с добавлением еще html, если у вас на сайте ссылки такого типа. Плагин WP No Category Base необходимо будет только активировать. Он сам сразу переделает все ссылки. По старым ссылкам с помощью редиректа будут открываться страницы уже без рубрик. Постепенно поисковые системы переиндексируют ваш сайт, и оставят в выдаче только новые ссылки.
Я пробовал отключить плагин уже после переиндексации. После перехода по ссылкам страницы сайта не открывались. Поэтому я отключать плагин не слтал. Если вы переживаете по поводу нагрузки, то могу вас успокоить. Плагин WP No Category Base практически никак не нагружает сайт при его загрузке.
Василий спасибо за столь подробный ответ, уже все сделала по вашей статье, сайт не пропал, значит все прошло удачно.
Вот по поводу ссылок, кроме того, что слишком длинное url, есть ли еще минусы использования ЧПУ как сайт-категория-статья? Вот постоянная зависимость от плагина, не очень удобно. И спасибо что обратили внимание на сей факт, об этом я не знала.
Для поисковых систем нет никакой разницы, есть ли в URL данной страницы рубрика или нет. Меня волновала не длина ссылки, а то, что мне нужно было увеличить количество рубрик на сайте, а затем переместить статьи в новые места. Если бы рубрик в URL не было, то тогда этот вопрос решился бы просто.
Данный плагин установлен на моем сайте, никаких неудобств от этого я не испытываю.
Василий, это снова я! У меня такой вопрос:
Я занесла данные о replytocom в вебмастер гугла и оставила этот параметр в файле robots.txt т.к. дублей у меня не было изначально именно по replytocom, то есть мне не нужно избавляться от дублей, а только на всякий случай предвосхитить.
Из чего вопрос: нужно ли предпринимать следующие шаги, а именно:
— вносить изменения в файл htaccess и function.php
— менять robots.txt
— устанавливать плагин древовидных комментариев?
Извини, если повторяюсь но уже запуталась в этом обилии информации)
Заранее благодарю!
Галина, по replytocom я у себя на сайте сделал так: удалил директивы из файла robots, внес изменения в файл htaccess, добавил код из этой статьи в файл function.php.
Редирект в htacess для того, чтобы робот перенаправлялся со старых дублей на страницу статьи. Если в данный момент, таких дублей нет в индексе, они еще могут там появляться со старых комментариев (мой случай).
После вставки кода в файл function.php новые комментарии будут уже без переменной replytocom в ссылке. В этом можно убедиться на моем сайте, если подвести курсор мыши к кнопке «ответить».
Если вставлен код, то использовать плагин WordPress Thread Comment нет необходимости. Если replytocom вообще нет, то можно установить этот плагин, ничего не меняя, если очень не хочется изменять другие настройки.
Василий, и еще — обнаружила у себя следующие дубли: page, tag, feed
Может напишите статью как от них избавиться? Думаю, вам много читателей будут признательны!
C такими дублями я поступил следующим образом.
Убрал соответствующие директивы из файла роботс, а в файл htaccess вставил такой код (там уже присутствует редирект с replytocom):
RewriteCond %{QUERY_STRING} replytocom= RewriteRule ^(.*)$ /$1? [R=301,L] RewriteRule (.+)/feed /$1 [R=301,L] RewriteRule (.+)/trackback /$1 [R=301,L] RewriteRule (.+)/comments /$1 [R=301,L] RewriteRule (.+)/attachment /$1 [R=301,L] RewriteCond %{QUERY_STRING} ^attachment_id= [NC] RewriteRule (.*) $1? [R=301,L]Новые редиректы я взял с сайта Борисова. Я раньше думал, как все это сделать редиректами, но нужного кода не знал. Александру нужно сказать спасибо за то, что этот код стал доступен для всех.
По моему мнению, это самый простой и оптимальный вариант решения проблемы.
Некоторые вещи, которые там советуют, я бы не стал делать на своем сайте. Например, добавление в файл function кода для 404 ошибки. А если таких ошибок будет огромное количество? Поисковики ведь могут принять санкции к такому сайту из-за таких ошибок.
Благодарю, Василий. Я и файл htaccess трогать опасаюсь, если честно. А еще Александр советует просто удалить все метки (tag). Вы это сделали? Мне как-то жаль просто так взять и все метки выкинуть.
Если опасаетесь, то тогда не трогайте. Используйте другие методы.
Наличие таких дополнительных страниц, содержащих в своем адресе tag, никакой пользы сайту не приносят.
Вообще метки не должны индексироваться, если в плагине All in SEO Pack включена соответствующая опция. На странице с тегом, плагин создает метатег роботс — noindex, который запрещает индексацию этой страницы с тегом. Только для этого, в файле robots не должно быть запрещения на индексацию тегов.
Лично я такие страницы безжалостно удалил в панели Гугла вручную. Потому что, не стал ждать, пока Google это сделает сам, через некоторое время.
Василий, у меня тоже опять возникли вопросы. В основном у меня дубли replytocom Следить стала недавно, но на всякий случай убрала 2 строчки нижние из robots.txt Хотя у меня такое впечатление, что моя тема не создает такие дубли и они сами потихоньку уходили. Сменила я эту тему в середине января. Как и писала уже ранее, дублей видимо было много. Статей на сайте на тот момент было больше 200. И сейчас все дубли replytocom только со старых статей. С новых статей нет. Но все равно тема дублей не дает покоя.
Попробовала как советует Борисов. Белого экрана я не увидела, но на сайт зайти не могла. Выдавало сообщение: «слишком много переадресации на сайте». Пришлось все вернуть по старому. Но дубли и другие есть. Одних больше, других меньше. Дубли с комментариев, trackback открываются нормально, на статьях без всяких приставок. Может и не нужно что то делать с такими дублями. У меня дубли страниц и с replytocom всего несколько штук открываются с этой приставкой. Остальные с нормальным УРЛ, без приставки replytocom. В панель вебмастера Гугл я занесла два параметра: replytocom feed. Просто этих дублей больше всего. Еще есть дубли с некоторых картинок. Открывается просто одна картинка. Хотя я ссылки на картинку убираю сразу после вставки в статью. Делать это стала пару месяцев назад. Поддержу Галину, может напишите еще по вопросам из комментариев статью.
Любовь, если у вас дублей не так много, то не стоит особо переживать по этому поводу. Понаблюдайте за ними, если количество дублей постепенно уменьшается, то тогда этот вопрос будет решен через какое-то время.
Можете добавить код в файл function.php из этой статьи. Новых дублей с replytocom на вашем сайте уже точно не будет.
Новую статью писать не буду, потому что это не моя тематика, я все-таки не специалист по этой теме.
Дубли страниц — это только один из возможных факторов для понижения сайта в результатах поисковой выдачи. Когда вы читаете на некоторых сайтах, что только из-за этого сайты не попадают в ТОП выдачи, то вы должны понимать, что это во многом, маркетинговые штучки. Поисковики анализируют статьи по многим параметрам, и не факт, что отсутствие дублей продвинет какой-нибудь сайт в поисковой системе. Полгода назад на моем сайте было огромное количество дублей, тем не менее посещаемость у сайта была хорошая.
Подскажите, а если не делать редирект на replytocom, дубли сами отвалятся или никак? Просто не очень хочется редиректы ставить. Спасибо.
Для того, чтобы не появлялись новые дубли, поставьте код из статьи, или используйте один из плагинов.
Как я понял из статьи на стороннем ресурсе, то на страницах replytocom есть такая вещь как, что не даёт новым страницам индексироваться и соответственно создавать новые дубли. Вроде как это должно работать или мнение ошибочное? И изначально вопрос был, если не ставить редирект, уже существующие дубли потихоньку сами отвалятся или нет?
Не отобразилось:
Я понял. Да, если запрета на индексацию в файле robots.txt нет, то при наличии на страницах с дублями метатега роботс, такие страницы не должны будут индексироваться поисковиками. Уже существующие дубли должны будут постепенно удаляться из выдачи.
Никогда не стоит что-то делать импульсивно типа того: «кто-то сказал что так надо, а возьму и я также сделаю…»
После прочтения статьи Борисова я не поленился задать вопрос в техподдержку Яндекс о том, стоит ли убирать запрет в robots.txt на индексацию страниц тегов,replytocom и пр. из-за того, что на этих страницах все равно есть тег noindex.
Получил ответ о том, что делать они ни в коем случае не рекомендуют (!!!) ибо в этом случае робот будет тратить кучу времени на их чтение, а до полезного контента может и не дойти. Исключение же роботом дублей из-за запрета их индексации в robots.txt (далее цитирую) «никак не влияет на Ваш сайт».
Еще раз убеждаюсь, что «гуру» развелось много, а тех, кто готов им слепо верить, еще больше…
Интересный ответ Яндекса. Но дело в том, что Яндекс и так не индексирует все эти страницы. Все эти советы в большей степени касаются Google. У себя я метатега роботс не нашел, поэтому я на эти теги и не надеялся, не принимал их во внимание.
Я сейчас наблюдаю за действия поисковых систем на своем сайте. Пока я могу сделать такие выводы.
Я убрал в файле robots те директивы, на которые был сделан редирект в htaccess. Из-за того, что я убрал соответствующие директивы, в Яндексе увеличилось количество страниц загруженных роботом, в индексе все осталось как и должно было быть.
В панели Google постепенно уменьшается количество URL с replytocom, а после удаления из файла robots директивы с feed, начало уменьшаться количество отслеживаемых страниц с feed.
Какие можно сделать выводы, принимая информацию от тех.поддержки Яндекса?
Если после удаления соответствующих директив, Яндекс начал увеличивать количество загруженных роботом страниц, то в той части файла robots, которая касается Яндекса можно будет вернуть назад соответствующие директивы.
А ту часть, которая предназначена для роботов остальных поисковых систем, я пока оставлю без директив. После удаления всех дублей из «недр» сайта запрещающие команды можно будет снова вернуть на место. В результатах поисковой выдачи дублей у меня нет, но на сайте они пока есть, Google за ними следит и постепенно удаляет.
По той схеме, что сделана на моем сайте, теоретически все должно происходить таким образом. Робот переходит на дублированную страницу, а оттуда он сразу перенаправляется с помощью 301 редиректа на основную страницу. Поэтому такие страницы вообще не должны быть проиндексированы.
Как оно там на самом деле, знают только сами роботы и очень небольшое количество специалистов поисковых систем.
Василий! Я тоже у себя в коде не вижу метатега, который установлен в файле функции. Думала, что он не работает, а он вдруг заработал в Яндексе, когда вернула запреты в чекбоксах Platinum Seo Pack.
В .htaccess у меня пока нет кода, скопировала его сейчас, у вас, в свой блокнот. Спасибо, может пригодится.
Я не знаю, как вы реализовали установку запретительного мета тега. Вариантов два: использовать плагин, или вставить соответствующий код на сайт.
Сергей время расставит все по своим местам.
Согласен, Александр!
Я только сейчас читала в Гугле, что не нужно делать запреты в файле robots.txt при наличии запретительного метатега. Я тоже обращалась в Яндекс поддержку по поводу метатега. Получила ответ, что запреты нужно оставить в SEO плагине, потому что их видно в коде, чтобы не было противоречий с запретительным метатегом. Когда так сделала, в Яндексе появились заблокированные страницы. Гугл до настоящего времени метатега не видит, уже месяца 4 прошло.
Василий, в функции темы я код поставила. Как проверить что он работает?
Когда подведешь курсор мыши к кнопке «ответить», то в левом нижнем углу, в ссылке на страницу уже не будет replytocom. Если нажмешь на кнопку «ответить» и откроешь страницу в новой вкладке, то в ссылке на новой странице также не будет replytocom.
Василий, привет еще раз! Я насчет функции function replace_reply_to_com
Ты пишешь, что «после этого при наведении курсора мыши на кнопку «Ответить» в комментариях, в ссылке, которая будет видна в левом нижнем углу окна браузера, теперь не будет появляться переменная replytocom. Следовательно, новые ссылки с этим параметром не будут добавляться в индекс поисковых систем».
Но тогда будут создаваться дубли такого вида: http:/site.ru/…html#comment-…, которые уже даже не редиректятся.
То есть мы просто заменим шило на мыло, разве нет?
Ольга, поисковики не индексируют страницы, в окончании которых имеется хеш тег решетка. Поэтому такие страницы не являются дублями.
Ок. Но я все ж через span прописала и все. Кстати, Василий, а как ссылку на авторов комментариев закрыть? Пытаюсь через тот же span (с припиской в js), но что-то никак.
Как закрыть в span ссылки я не знаю, пока этого не делал.
Василий, подскажите пожалуйста, вот эти «игры» с роботсом влияют на индексацию, в том плане, что меняешь роботс и долгая индексация новых статей? После того как я его поменяла Яша не хочет индексировать новые статьи. В чем может быть причина? До этого индексировались буквально в течении двух минут.
На индексацию статей изменения директив в файле роботс влиять по идее не должны, мы же не закрываем статьи от индексации. А как на самом деле будут поступать поисковые системы неизвестно. Бывает, что индексируют все быстро, а некоторые статьи почему-то не очень быстро.
Василий, подсrажите, пожалуйста, в моем robots правильно ли я удалю такие строчки:
Disallow: */comments
Disallow: /category/*/*
Disallow: */trackback
Disallow: */*/trackback
Disallow: */*/feed/*/
Disallow: */feed
Disallow: /tag
Disallow: /tag/*
Disallow: /?s=
Я хочу это сделать только для гугла, а для Яндекса оставить так как есть, но там еще остаются такие строки, как Disallow: /feed/ и Disallow: /trackback. С ними как поступить?
Нигде не нашла, что означает Disallow: /?s= и подлежит ли это удалению? А может и у Яндекса поправить robots? Начиталась везде и у всех, пока не особо в robots соображаю, именно то, что касается со звезочками, и слешами. Испортить боюсь, где-то говорят, что не стоит копировать у других robots. Хочу начать с сайта, на котором пока не много посещаемость, исправить. Потом хочу после robots добавить эти теги в инструменты гугла и добавить код в htaacess и на этом успокоиться.
Как я поняла в файл function не стоит ничего вносить. Прочитала все комменты. Сайт взяла в закладки, подписалась, очень интересно и доходчиво пишите. Чувствую, что вопросов у меня будет немало, но надо начинать бороться с дублями. Я уже давно ищу информацию на эту тему, а тут такой прорыв. Спасибо.
Некоторые эти директивы дублируют друг друга. Проверить работу файла роботс можно из панели вебмастера Яндекса и Гугла.
Директиву со знаком вопроса уберите из файла. Посмотрите, какие на вашем сайте есть дубли.
Как удалить replytocom написано в статье. Есть разные варианты решения проблемы. Я выбрал вариант борьбы с помощью файла htaccess. У меня также добавлен код из статьи в файл functions для предотвращения появления replytocom.
Для удаления других дублей, я сейчас также использую htaccess (код есть в статье). При использовании такого варианта нужно будет удалить соответствующие директивы из файла роботс.
Дальше необходимо будет наблюдать за количеством дублированных страниц в индексе, следить за динамикой удаления. Если все идет нормально, то постепенно дубли будут удалены с вашего сайта.
Василий, спасибо. Подглядела Ваш robots, передела под себя. У меня был очень большой, ничего непонятно. Мне в свое время настраивал программист, я не вникала особенно. Теперь во все тонкости приходится влезать, в файл htaccess занесла, ничего не свалила.
Буду наблюдать и ждать результаты. Интересно, все эти роботы давно кочевали по интернету, даже в школе Старт Ап мне так советовали, а теперь оказывается, все неправильно. Интересно? Может еще что такое обнаружится? Сейчас еще про разметку и обилие ссылок говорят. Тоже, наверное, меры надо принимать какие-то. В любом случае буду наблюдать, позиции не хочется потерять
Людмила, торопиться пока не нужно. Спокойно понаблюдайте за эффектом. Возможные проблемы лучше решать постепенно.
Все мы учимся на своих ошибках. Многие моменты узнаем опытным путем или от более знающих людей.
У меня результат 0 из 0… Что-то не так сделала или так и должно быть?
Мета теги должны отображаться только на страницах типа: сайт/page/2 и т.п.
Галина, у вас код из второй статьи Борисова?
Да, вот этот:
/*** ДОБАВЛЯЕМ meta robots noindex,nofollow ДЛЯ СТРАНИЦ ***/ function my_meta_noindex () { if ( is_paged() // Все и любые страницы пагинации ) {echo "".''."\n";} } add_action('wp_head', 'my_meta_noindex', 3); // добавляем свой noindex,nofollow в headУ меня, в моей теме, этот код вызывал «белый экран». Попробуйте его немного изменить: уберите первую строчку, а в последней строчке удалите текст начиная с двойной косой черты. У меня этот код заработал после такой модификации.
Перед изменениями не забудьте сделать резервную копию файла.
Василий, что-то я не решилась сразу менять htaccess У меня он сейчас такой:
RewriteEngine On RewriteCond %{REQUEST_URI} !^/~puchkovaso/puchkova-sofi.ru(.*) [NC] RewriteRule ^(.*)$ /~puchkovaso/puchkova-sofi.ru/$1Мне нужно после первой строки вставить две строки такие:
RewriteCond %{QUERY_STRING} replytocom= RewriteRule ^(.*)$ /$1? [R=301,L]Поясните пожалуйста. Этого достаточно или еще нужно менять код в Функции темы?
Софья, после «RewriteEngine On» вставьте код для того, чтобы работало перенаправление с уже проиндексированных страниц.
Сохраните старый файл htaccess (береженого бог бережет). Потом проверьте работоспособность перейдя по ссылке, которая содержит replytocom. Должна будет открыться оригинальная страница без replytocom.
Если добавите код в файл functions, то после этого, новые страницы с replytocom уже не будут появляться на вашем сайте.
Василий, большое спасибо. Как вы понимаете сама я до сегодняшнего дня файл htaccess не меняла. А сейчас первое что сделала — файл functions изменила, добавила код, посмотрела в комментариях перестали копии создаваться.
Затем одушевленная добавила в htaccess две строчки с replytocom. Сайт остался работоспособным. Но страница, где есть в ссылке это слово, так с ним и открылась.
Наверно потихоньку нужно удалять эти копии. Хотя один раз мне показывают, что у меня примерно 500 таких страниц, а иногда больше 5000.
Софья, ссылку с replytocom нужно вставить в адресную строку браузера и перейти по ней. Если открытая страница будет без этого параметра, то значит все работает должным образом.
Если нет, то попробуйте вставить код в самом конце своего файла htaccess.
Василий здравствуйте! Что-то я понять не могу, когда делаю поиск копий replytocom своего сайта, на первой странице мне пишут копий 4720, а когда перехожу на вторую страницу, там уже указывается всего 19, а страниц в поиске две. Чему верить?
Софья, верить нужно тому, что вы видите в результатах выдачи основного и дополнительного индекса. Вы нажимали на ссылку «показать скрытые результаты»?
Наша задача, сделать так, чтобы в результатах выдачи не было таких страниц.
Общая цифра может не соответствовать действительности.
Спасибо, Василий! Да, я нажимала на ссылку «показать скрытие результаты». До нажатия на эту ссылку вообще выходило, что у меня 1 неправильная страница.
Значит сейчас у вас более-менее все нормально. Страницы с этим параметром будут постепенно удаляться.
Вообще таких страниц может быть очень много, главное, чтобы их не было в результатах поиска. У меня, например, сейчас в панели веб-мастера отслеживается около 5700 страниц с replytocom, а раньше их там было более 8000.
Василий, ваш прогноз не сбывается. Вчера удалила 9 страниц в веб-мастере. Сегодня иду проверять копии страниц, а их еще больше стало 5750 и в поиске -23, вчера было всего 15. Василий, большая просьба к вам, набрать мой сайт puchkova-sofi.ru/ для поиска replytocom. И сообщите мне ваши результаты, если не очень трудно. Заранее спасибо.
Софья, у вас не работает 301 редирект. А почему вы не вставили код в файл functions? Подведите на моем сайте курсор мыши к кнопке «ответить», а потом посмотрите на ссылку в левом нижнем углу окна браузера. У меня нет в ссылке replytocom, а у вас есть, потому что вы не вставили код из статьи.
Поэтому ссылки с этим параметром и не удаляются с вашего сайта.
Софья, не все так сразу! Лично я результаты заметила не на следующий день, а гораздо позже. Но зато посещаемость с Google возросла на моем старом блоге inet-boom ru человек на 80 ежедневно.
Софья, вам такой файл htaccess кто-то специально делал? Он у вас не стандартный.
Можно же попробовать установить стандартный файл. Если ничего не делать, то тогда ничего не получится. Я же не боюсь экспериментировать, хотя мне есть, что терять. Были у меня и неудачные эксперименты.
Сохраните установленный сейчас файл htaccess на своем компьютере, а вместо него добавьте стандартный файл htaccess. Проверьте работу сайта, если все нормально работает, добавьте туда код с replytocom. Перед изменениями можно сохранить резервную копию сайта.
Потом удалите из файла robots директивы со знаком вопроса.
Василий, файл htaccess мне никто не делал, я даже не знала о его существовании. Просто на бесплатных уроках Твоего Старта научили пользоваться Вордпрессом, установила один готовых шаблонов и все. Дальше вперед и с песней, как говорится, разбирала, что могла сама, читала блоги, что могла изменяла. Раз говорите, нужно пробовать, буду пробовать. Надеюсь, с вашей некоторой помощью. В принципе могу и заплатить разумные деньги. Но поскольку на сайте ничего не зарабатываю, пытаюсь делать сама, да, мне это и интересно.
Пробуйте. Я сам файл htaccess первый раз открыл полгода назад. А сейчас, я много чего туда добавил.
Василий, вы меня просто «убили», когда я у себя на сайте подвожу к кнопке Reply ответить, у меня нет в ссылке replytocom. Я не могу послать скриншот, так как, чтобы его сделать мышку нужно убрать с этого слова. И я вставила 301 редирект в файл functions.
Письмо вам отправила.
Да, код работает. Я смотрел, наверное, страницы из кэша. Сейчас вы сбросили кэш, все заработало.
А перенаправление с replytocom со старых статей не работает.
На счет добавления редиректов в htacess, я бы не стал этого делать, это же сколько получится внутренних редиректов — грузилово для сайта, я так понял-здесь всего двух вещей хватило бы: удаления директив с роботс, и добавление компонента replytocom в панеле вебмастера гугл, и все! Как вы считаете?
Эти перенаправления не так уж страшны. С 301 редиректом дубли точно будут удаляться, а без него этот процесс может занять очень много времени.
А разве нужно открывать replytocom в robots.txt, если добавляешь параметр replytocom в гугл вебмастер? Обычно при удалении любого url через панель вебмастера гугл, этот url должен наоборот быть закрыт в роботс или отдавать 404 ошибку. Мне кажется вы тут неправильно написали.
Янис, способ борьбы с дублями replytocom, описанный в моей статье работает, в чем я убедился на собственном опыте. Это лично мои наблюдения, которые, действительно работают.
Если вы хотите удалить дубли страниц со своего сайта, то тогда вам лучше будет убрать директивы с вопросами из файла robots. Если вам кажется, что я не прав, то вы можете поступить по другому.
Василий, здравствуйте! У меня еще вопросик. А как я смогу узнать, что у меня все дубли удалились?
Софья, в панели веб-мастера.
«Индекс Google» -> «Статус индексирования». Количество проиндексированных страниц постепенно будет уменьшаться.
«Сканирование» -> «Параметры URL». Количество отслеживаемых страниц с replytocom будет уменьшаться.
Я сначала закрытыми подержу и через параметры поставлю не сканировать, того что если открыть, всеядный гугл может и в основной индекс кидануть все! Тут еще многое от шаблонов зависит, я бы не спешил так рьяно открывать все, и по схеме Борисова нужно быть очень осторожным, я ее не решился использовать…
В основной индекс Гугл ничего не накидает, потому что робот будет перенаправляться с дублированной страницы на основную страницу. Шаблоны в этом случае, не играют никакой роли. Редирект с replytocom и добавление мета тега роботс точно работает. По остальным редиректам, я пока наблюдаю их действие.
Василий, здравствуйте. Подскажите) Я прочитала, что вы сменили шаблон. Как правильно это сделать? Надо ли отключить все плагины перед сменой шаблона?
Плагины лучше отключить, а потом включать по одному проверяя совместимость плагинов с новой темой. У меня мало плагинов, поэтому я ничего не отключал, а просто заменил тему.
Спасибо Василий. У меня тоже 9 плагинов — это немного, но всё же есть) Попробую всё проделать сначала на локальном хостинге (Денвере).
Что-то у вас совсем мало плагинов. А я сайт делал сразу на хостинге, с Денвера переносить-это мороки уйма!
У меня также 9 активных плагинов. Мне вполне хватает такого количества. Остальные плагины включаю, по мере надобности, на короткое время.
Янис, у меня как у Василия — 9 активных плагинов, остальные отключаю. А Денвер установлен для экспериментов. Согласна переносить морока.
Прочитала. Очень много полезной информации, спасибо, вроде бы всё написано профессионально и доступно, но именно я, так и ничего и не поняла… Меня тоже смущают эти дубли, и сам этот robots.txt, я уже запуталась, что и куда писать, удалять, вставлять…
В общем не обессудьте, я чайник в этих делах. Очень прошу Вашей помощи, если можно, посмотрите этот robots.txt, на моём сайте. И подскажите, что сделать, если конечно Вам не трудно: replytocom нет у меня, но feed, tag навалом. Что с этим делать? В интернете много разного, ответов на любой вкус, и нужно убирать и не нужно убирать, и какой должен быть этот правильный robots.txt. Не хочется больше искать, если можно, хотела бы услышать совет профессионала.
Я совсем не профессионал в этой теме. Это мой собственный опыт, не претендующий на истину в последней инстанции.
У вас в robots.txt запрещена индексация feed, тем не менее, таких страниц в дополнительном индексе очень много. Значит, что-то работает не так как надо.
Как именно, в данный момент, осуществляется с дублями на моем сайте я написал разделе статьи — «Как удаляются дубли на моем сайте».
В файле роботс моего сайта, после Disallow: /wp-content/themes, были удалены все остальные директивы. В данный момент, я наблюдаю за удалением дублей, динамика положительная.
Здравствуйте. Вы пишите что строчки:
RewriteCond %{QUERY_STRING} replytocom= RewriteRule ^(.*)$ /$1? [R=301,L]Необходимо вставить ниже RewriteEngine On
А я читал в некоторых блоках, что ставить нужно выше перед # BEGIN WordPress Так все таки где вставлять?
Я написал о том месте, где эти строчки вставлены у меня на сайте. Если вы считаете, что этот код необходимо вставить в другое место, то вы можете сделать так, как вам советуют другие.
Ну прям дублемания какая-то. Теперь каждый уважающий себя блоггер должен написать пост про поиск и удаление дублированных страниц)
Привет, Василий!
Пост у тебя получился самым полным и самым интересным из всех, которые я читал (даже мой родной мануал поскромнее выглядит на фоне твоей публикации)! Молодец!
Максим, спасибо. После прочтения твоей статьи, я решил поделиться своим опытом. Как раз, в этот момент, на моем сайте произошли положительные изменения.
Еще долго думал писать эту статью, или нет. Знал, что особой пользы эта статья моему сайту не принесет, только будет большое количество комментариев.
Успел опубликовать даже раньше, чем один известный блоггер. А после его публикаций, в интернете пошла лавина статей об этой проблеме с реферальными ссылками.
Да, я помню этот момент появления лавины — прямо уж голова гудела от анонсов по дублям. Но твой пост самый лучший!
Спасибо, Максим.
Василий, здравствуйте! На старом сайте уже давно ничего не проверяю, надоело, если честно. Как внедрила все рекомендации Борисова, так и живу. Но сегодня на меленьком бложике посмотрела индексацию Яндекса и ахнула, там статей очень мало, проиндексированных Яндексом страниц было 12-14, а сейчас 62! Стала смотреть, проиндексировались все фотографии! То же у Гугла.
Не эти ли строчки роботса тому причиной:
User-agent: Googlebot-Image
Allow: /wp-content/uploads/
User-agent: YandexImages
Allow: /wp-content/uploads/
И правильно ли это? Простите, если туплю. Я не очень во всем этом разбираюсь.
Как я думаю, в индексе, в идеальном случае, должны быть только статьи сайта и отдельные страницы. Если туда добавлены изображения со страниц сайта, то, возможно, они создают дубли, если адрес ссылки будет практически одинаковый.
Как я вижу по своему сайту, таких картинок в выдаче у меня нет, но если посмотреть на показатели сайта в SEO программах, то там выводятся цифры, которые говорят о том, что поисковики проиндексировали столько-то изображений. Выходит, что они их индексируют, но не помещают в список проиндексированных страниц.
Возможно, эти команды сыграли свою роль. Не все следует буквально повторять. Я, например, уже несколько раз менял файл robots.txt, потому что не все, что работает в Google, будет работать таким же образом в Яндексе. Я вижу это по динамике добавления или удаления страниц в поисковых системах.
Спасибо за разъяснения! Поскольку я сама не могу придумать, как написать роботс, потому и следую буквально. Что же делать, нам, неграмотным крестьянам?! Приходится слушать гуру. Я уже жалею, что вообще что-то стала менять.
Теперь вот думаю, вернуть все, как было или с отдельными строчками экспериментировать?
Галина, наверное, не стоит все кардинально менять. Можно будет попробовать удалить директивы с Allow и посмотреть, что будет дальше.
Здравствуйте, хочу присоединиться к вашему разговору, так как слежу за комментариями к этой статье. У меня к сожалению дубли прыгают, то больше, то меньше. В основном эти показатели изменяются в Гугл, Яндекс стабилен).
Вот жду когда это закончится! Ничего не меняю.
У меня, наоборот, показатели в Гугле приходят в норму. В Яндексе то почти все идеально, то опять добавляются дубли в индекс. Яндекс добавил в индекс страницы навигации, хотя у меня на этих страницах стоит метатег роботс noindex. Не должен был Яндекс этого делать.
А я поборол дубли replytocom именно с помощью плагина SEO Yoast, отказавшись от All In One Seo Pack.
Да, я писал об этом в этой статье. Плагин WordPress SEO by Yoast справляется с этой проблемой.
У меня тоже был реплитоком, но только давно. Убрала в настройках сайта вложенность комментариев и забыла про реплитоком. Думаю, что не так уж ценны вложенные комментарии, простые тоже хороши. Я вообще по сайтам редко хожу, здесь что-то разговорилась.
Если комментариев много, то портянку с комментариями, где неизвестно кто кому, что ответил, невозможно читать.
У меня странный случай, в гуле нет дублей страниц, а вот программой XENU их находит.
Прогнал свой сайт программой XENU и обнаружил нехорошее) Программа нашла пустые ссылки,то есть 335 страниц в одной. То есть это дубли существующих страниц,причем всех страниц. При чем без всяких фидов на конце,дубль страницы один в один.
Собственно у меня на двух сайтах такая беда, одном на вордпресс и другом на дле. Видимо поэтому индексация ужасная у них.
Я думаю, может дело в кириллическом домене?
Главное, чтобы дубли не находили поисковые системы. Возможно, у вас плохая индексация из-за кириллического домена.
Знаю, что на моем блоге есть дубли, но когда проверяю сколько страниц в индексе Гугла (в основном и дополнительном) и вхожу в конец списка, то надпись «показать скрытые результаты» не появляется. В чем причина и как найти дубли?
Надежда, у вас много дублированных страниц с replytocom, посмотрите еще feed и page.
Вот еще полезная штука:
remove_action ( 'wp_head', 'wp_shortlink_wp_head', 10, 0 );Если вставить в файл functions.php, то в html коде одиночной записи исчезнет зловредная строка с
rel=’shortlink’.Кстати, на данный момент у тебя она тоже есть.
Прочитал про это. Это нужно для создания короткой ссылки без использования посторонних сервисов. Google правильно обрабатывает эту ссылку, да и Яндекс тоже. На странице сайта есть
link rel="canonical", поэтому у меня, наличиеrel='shortlink', на появление дублей влияние не оказывает.Я так понял, здесь работает редирект через
rel="canonicalи вставка данного кода абсолютно не нужна?Да Влад, этот код мне ничего не даст. Таких дублей у меня нет и не было.
Для тех у кого есть (на всякий случай): в robots.txt должно быть открыто ?p=, только тогда редирект будет работать нормально и все shortlink удачно будут вылетать из выдачи.
Хороший сайт у вас, Василий! А сколько примерно требуется времени, пока дублей не будет на сайте?
Это смотря сколько дублей. У меня было очень много, особенно в Google. Если смотреть на статус индексирования в Google, то у меня количество проиндексированных страниц уменьшилось с 7139 (8.12.2013) до 529 (19.10.2014). Если дублей достаточно много, то основная масса уйдет минимум за полгода, а то и за большее количество времени.
Спасибо большое, Вы очень мне помогли в плане последних событий с этими дублями и горе СЕО плагином, который нам не пришлось сносить. Но все-таки я не пойму как быть с файлом роботс по поводу запретов таких стандартных тем как: feed, tag, page, comment-page, attachment, attachment_id, category, trackback.
Все это нужно открывать?
Я бы не назвал AIOSP горе плагином. Ситуация, которая всех взбудоражила, в нормальных условиях вообще не возникнет. Могут быть проблемы, если что-то сделать намеренно. Да и в настройках самого плагина, даже без добавления всяких изменений, есть несколько рубежей защиты.
У меня в файле robots нет этих параметров, все открыто.
Василий, здравствуйте. Мой вопрос, может быть не совсем по теме.
При решение проблемы с canonical я хотел вставить код 301 редиректа в файл .htaccess, предложенный Максимом Зайцевым, и с удивлением обнаружил, что этот файл перезаписан на стандартный, который создается при установке WP. Хостер, к сожалению, в решении этой проблемы помочь мне не смог. Файл я конечно поправил. А в комментариях к той статье Максима Вы написали, что сделали запрет на изменение файла .htaccess.
Не подскажите, можно ли таким запретом предотвратить появление подобной ситуации с изменением .htaccess? Если да, то как установить запрет на не санкционированное изменение этого файла?
Валерий, войдите на свой сайт при помощи, например FileZilla, затем нажмите правой кнопкой мыши по файлу htaccess, в контекстном меню выберите пункт «права доступа к файлу». Там поменяйте цифровое значение с 644 на 444. После этого файл htaccess не будет изменяться.
Если вам нужно будет снова что-то поменять в файле htaccess, то тогда снова поменяйте права доступа к файлу на 644, сделайте изменения в файле, а потом, если снова захотите запретить изменения в этом файле, верните на файл права доступа 404.
Решил тоже проверить файл и увидел что и у меня изменился, вот что значит подписаться на новые комментарии к статье)
У меня появился маленький вопрос, у меня дублей feed, было почему то меньше чем статей, но я вот тоже решил от них избавиться, добавил в htaccess:
RewriteRule (.+)/feed /$1 [R=301,L](правильно, да?). Поначалу вроде они начали отваливаться, но потом опять вернулись (htaccess убрал же изменения по редиректу). К своим 60 + (притом что статей 178), но если раньше с feedом на окончании открывались полноценные статьи и сразу редиректились, то теперь открываются не статьи, а подписаться на ленту и комментарии и ничего не редиректится. Или я что-то сделал не так или что?И по поводу статьи, все дубли реплитуком, страниц и тэгов ушли без редиректа, гугл до этого (конец июня) посещалка была около 150 человек, как всё начало уходить, посещаемость с гугла начала расти и в сентябре доходила уже до 350, но 23 сентября сайт попал под Панду и всё, имею 10-20 переходов с гугла. Что не так, я так и не разобрался. Есть предположение, что из-за того что мои рецепты копировали в ЛиРу, могла потеряться уникальность. Хотя чисто по логике, если на 30-50-10 страницах один текст и он ссылается на меня, то от этого, должен был бы быть только плюс.
Да, любой запрет фидов, для гугл в роботс, я убрал.
А почему у вас файл htaccess убрал изменения по редиректу?
По поводу Панды ничего сказать не могу. Поведение поисковиков не всегда бывает логичным. Может у Google еще сработали какие-то алгоритмы.
Вопрос с подвохом? А у Валерия почему htaccess убрал изменения по редиректу? Я не знаю почему. Но я такое уже неоднократно читал, что он возвращается сам к первоначальному виду. Поэтому я поменял значение на 444, как вы предложили Валерию. Но редирект не работает?! Или я что-то не то смотрю? Вы не подскажите?
Да, у вас перенаправление не работает. Я проверил у себя, все работает.
А вы весь код туда вставили? Посмотрите файл, может вы где-то ошиблись.
Файл htaccess изменяется при изменении настроек в WordPress. У меня он изменялся из-за плагина безопасности, поэтому я ввел запрет на изменение настроек файла.
Весь это какой? у меня дубли только фид, я вставил этот
RewriteRule (.+)/feed /$1 [R=301,L], когда я его ставил неделю назад, он работал.Попробуйте вставить код из этой статьи и проверьте. От того, что у вас нет соответствующих дублей, от этого кода хуже вашему сайту не будет. Вы просто проверите работу 301 редиректа. Кроме вас же никто не сможет узнать, почему у вас не работает редирект. Для решения возникшей проблемы, нужно пробовать разные варианты.
Odessit, действительно htaccess вернулся к первоначальному виду. Почему не понятно. Если кто подскажет, буду благодарен. А по поводу редиректа, то он отлично работает и при правах доступа 444. На это грешить не надо, у Вас скорее всего причина в другом.
Здравствуйте, Василий подскажите пожалуйста. Я ещё летом в гугле в инструментах для вебмастеров прописал «feed», но на счетчике как стоял ноль, так и до сих пор показывает ноль. А «feed» как появлялись так и появляются. Но я не удалял с файла «robots.txt» директиву «feed». Если я правильно вас понимаю, мне надо с раздела в robots «User-Agent: *» удалить директиву «feed», а в разделе для Яндекса «User-agent: Yandex» эту директиву оставить.
В данный момент, я убрал эту директиву (feed) с robots в разделах Яндекса и Google. Для того, чтобы ссылки с feed постепенно удалялись, нужно убрать соответствующую директиву из файла robots.txt.
Здравствуйте, Василий подскажите пож. У Александр Борисов прочитал статью про скрытую опасность плагина All in One SEO Pack проверил у себя тоже есть такая проблема. Он советует плагин Platinum SEO PACK но он уже не обновлялся год. Я посмотрел у вас код страницы, если я правильно понимаю Вы тоже используете плагин All in One SEO Pack но проблем с «canonical URL» у вас нет.
Подскажите, как Вы решили эту проблему?
Радик, переход на плагин Platinum SEO — это не лучшее решение. При переходе не решается проблема отдельных страниц.
Можно остаться на плагине AIOSP и решить эту проблему. Сначала следует настроить сам плагин:
1. В настройках плагина нужно активировать пункт «No Pagination for Canonical URLs:».
2. Активируйте в настройках плагина пункты «Use noindex for paginated pages/posts:» и «Use nofollow for paginated pages/posts:».
После этого, на таких страницах будет отображаться ссылка на каноническую страницу и на страницу будет добавлен мета тег роботс noindex,nofillow.
Далее можно еще добавить в файл functions.php код, в самом начале файла, сразу после php:
add_filter('aioseop_prev_link', '__return_empty_string' ); add_filter('aioseop_next_link', '__return_empty_string' );После этого, на таких страницах (с цифрами на конце) не будут выводится ссылки с prev и next.
Также еще можно добавить 301 редирект в файл htaccess.
Для сайтов, которые имеют html в окончании ссылки, подходит такой код:
Для сайтов, ссылки на которых заканчиваются слешем (косой чертой):
RewriteCond %{REQUEST_URI} !(/page*) RewriteRule (.*)\/([0-9]+/)$ /$1 [R=301,L]Для других сайтов, подойдет такой код:
RewriteCond %{REQUEST_URI} !(/page*) RewriteRule (.*)\/([0-9]+) $1 [R=301,L]Теперь, после перехода по ссылке с цифрой на конце, будет открываться оригинальная страница.
Подробнее об этом можете прочитать в этой статье:
На самом деле это не баг, разработчик специально внедрил ссылки с prev и next. Они нужны для сайтов-магазинов и т.п. Просто другие SEO плагины еще не внедряли эти новшества Google. Тем более, в обычной ситуации такие ссылки вообще не должны появляться.
Василий, вот вы пишите:
Можете объяснить о каких страницах в данном случае идет речь?
Влад, если добавить к отдельной странице («о сайте», «карта сайта» и т.д.) слеш и цифры, а потом посмотреть исходный код этой страницы, то тогда в плагине Platinum SEO можно увидеть ссылку с canonical, а также мета тег роботс index,follow, то есть указание поисковым роботам индексировать эту страницу.
Василий, статья получилась просто всеобъемлющей и вполне понятной, спасибо, процесс удаления дублей страниц запущен, буду следить за результатом. Прада вручную еще не удаляла страницы из гугл вебмастера.
Рашида, если процесс запущен, то тогда придется некоторое время подождать результата. Процесс этот не быстрый, постепенно дубли будут удаляться.
Здравствуйте, Василий подскажи пож. эти директивы относятся к поиску на сайте? То есть они получается закрывают от индексации страницы поиска?
Disallow: /*?tag=
Disallow: /*?cat=
Disallow: /?pg=
Disallow: /*?paged=
Disallow: /*?m=
Disallow: /*?s=
Disallow: /*&s=
В плагине All in One SEO Pack есть функция {Use noindex for the Search page:} Используйте NoIndex для страницы поиска:
Как Вы думаете может тогда убрать эти директивы с robots?
Можете убрать. У меня на сайте нет таких директив в этом файле. Не все эти директивы относятся к поиску.
Почти все эти команды можно было выразить в одной директиве:
Если вы используете добавление метатегов к определенным категориям вашего сайта: поиску, архивам, категориям и т.п., то в этом случае, вам нужно будет удалить запрещающие директивы из файла robots для того, чтобы роботы перешли на данную страницу и видели метатег роботс:
Василий, здравствуйте! Прошу прощения, что снова возвращаю Вас к этой теме! Я сама, как внесла все предложенные Сашей Борисовым изменения в роботс.тхт, htaccess и Google Webmaster, это уже по Вашему предложению, так старалась больше этим вопросом не заниматься. У меня просто мозги начинают закипать, когда я пытаюсь во все это вникать.
Поскольку положение с Гуглом совершенно не улучшилось, а дублей replytocom у меня и так не было, теперь думаю, что я зря все это вообще затевала. Хоть обратно меняй! Боюсь только, htaccess снова трогать.
Пока я на эту тему размышляла, меня Яндекс очень сильно опустил в позициях по многим запросам, в начале прошлого месяца. Опустил реально круто. Те запросы, которые были на 1-3 позиции, стали на 7-8, но таких мало, а вот те, которые были на 8-12 позиции, улетели аж за 30-40-50… До последнего «апа» народу с Яндекса приходило 800-900 человек в сутки, а сейчас еле-еле за 100 переваливает! И вот я все пытаюсь разбираться почему это произошло.
Стала все снова проверять. У Гугла, как я понимаю, у меня дубли идут в основном на изображения. Уж не знаю, что я там делаю не так. Видимо, он меня за них держит под фильтрами. Недавно стала скрывать адрес картинки, чтобы не показывался при наведении курсора, не знаю, поможет это, или навредит. Посмотрим.
Стала копаться и в Яндекс вебмастере, нашла, что именно вначале ноября резко выросло количество ошибок по неканоническим урлам, с 3 до 20! Может это и было причиной немилости Яндекса, не знаю. Что делать с этими неканоническими документами, тоже не знаю.
Вот решила у Вас спросить, ничего не приходит на ум, что мне еще проверить, почитать, изменить?
Галина, а что именно не улучшилось в Google? Зачем менять код в htaccess? Он ничего плохого не делает. По поводу изображений, вы же знаете, что нужно удалить в файле robots.txt следующие строки:
Роботы сами проиндексируют изображения, если сочтут, что это необходимо сделать. Зачем заставлять поисковиков индексировать все изображения? Вот они взяли и все проиндексировали…
Галина, если у вас изображения не увеличиваются, то тогда уберите ссылки с таких изображений.
В Яндексе страницы не вылетели с индекса, а только понизились? На Яндексе был недавно какой-то поведенческий апдейт. Может это это его действие, хотя конечно, такое уменьшение посещаемости сразу в разы непонятно. Напишите Платону, может они вам скажут в чем дело.
Василий, спасибо за советы! htaccess менять не буду, поняла. Строчки в роботс удалю, там скоро вообще ничего не останется, он и так малюсенький.
В Гугл не улучшилось мое положение в выдаче.
Да, в Яндексе только все сильно понизилось в выдаче и в разы упала посещаемость. Я специально прошлась по многим знакомым, у всех все нормально, только у меня так. Ну почему у меня опять не так?! А теперь еще и слайдер сломался и реклама новая не работает. Мне, наверное, в очередной раз дают понять, что это не моё, а я упертая, все продолжаю барахтаться, вместо того, чтобы делом заняться.
Сейчас изменилось поведение поисковых роботов, поэтому файл robots.txt также изменился. Раньше можно было добавить директиву, роботы ее выполняли. А теперь это только рекомендация, хорошо еще Яндекс, в целом, выполняет команды из этого файла.
Положение в выдаче Гугла могло увеличится у тех, кто находился под каким-либо фильтром. Мой сайт, например, находился под фильтром в Гугле, поэтому после удаления дублей увеличилась посещаемость с этой поисковой системы.
Поинтересуйтесь все же у Яндекса, что случилось. Если вы ничего не меняли, то и предположить даже нечего. Не сдавайтесь! Мы такие же любители, у нас тоже бывают проблемы.
А может убрать слайдер? Он влияет на скорость загрузки, у вас с этим проблемы, посмотрите в PageSpeed. Повысится скорость загрузки — возрастут позиции в выдаче.
Василий, прошу прощения, что надоедаю. Платонам написала, не отвечают, у Борисова на блоге написала, рекомендует записаться на анализ блога. Если бы я знала, что это поможет. Сейчас перечислит мне список проблем, а как их исправлять, кто его знает.
Можно конкретный вопрос задам? У меня сейчас проиндексировалась новая статья, я сделала запрос в Яндексе, чтобы проверить, и вместо одной строчки с самой статьей, выдалось целых 6, то есть, каждая картинка выдается отдельно.
Раньше я им не давала названия, были img с номерами, сейчас даю название латиницей, по одному ключевику, но с разными номерами, вот все и индексируются. Ведь так не должно быть? Это дубли?
Яндекс так быстро не отвечает, тут еще выходные были. Если пришлют отписку, напишите еще раз.
Ольга, наверное, права, появление таких дублей — это особенности шаблона. У меня изображений на сайте намного больше, но, что на первом шаблоне, что на этом, таких дублей вообще не было.
Не знаю, что там будет за анализ, стоит ли его делать. Одно могу сказать точно, что не все его рекомендации стоит слепо выполнять.
То что вы меняли файл robots.txt, ничего страшного в этом нет. Я, например, его менял уже раз десять.
Попробуйте установить плагин, который рекомендовала Ольга. Возможно, тогда эта проблема разрешится.
Галина, Василий извините что вмешиваюсь. Просто слежу за комментариями к этой статье, так как подписана.
Галина, возможно, у вас проблема такая же как у меня была с Attachment (фото) я посмотрела в выдаче Гугл, например, mir-domohozyaiki.ru/prostoj-retsept-piroga-s-vishnej/retsept-prostogo-piroga-s-vishnej-1-2/
Самый простой способ поставьте плагин, который выкинет их из выдачи очень быстро. Можете прочитать статью у меня «Как избавиться на WordPress от страниц вложения attachment». Потом, плагин удалите.
Оля, наоборот, спасибо, что вмешиваетесь! Я благодарна за всякий совет!
Я обязательно прочту статью про плагин.
Вот говорят «не буди лихо, пока оно тихо», не было у меня особенно много дублей, не надо было влезать в роботс! А теперь не знаю, как расхлебывать…
Галина, и шаблоны у нас с вами одного автора, может поэтому и проблемы одинаковые. Вы обратите внимание, как вставляете фото в статью, возможно, вам как и мне надо добавлять, как Медиафайл обязательно, иначе идут отдельные страницы вложения.
Да, меня эта мысль про шаблоны тоже посетила!
Я добавляю фото сразу в статью, через Медиафайл не пробовала. Напишу там у Вас…
Василий, спасибо за такую подробную статью. В инструментах вебмастера Гугла я давно уже добавил replytocom в исключение сканирования. А вот, что параллельно надо убрать директивы из роботс, как-то не додумался. Прямо сейчас добавил код в .htaccess и удалил соответствующие директивы из robots.txt. Но около 2000 replytocom. Долго же мне ждать придётся.
У меня в мае, в параметрах URL было чуть больше 8000 replytocom, а сейчас стало уже 4200.
В индексе Google в декабре 2013 года было 7139 страниц, а сейчас, год спустя — 420.
Постепенно всевозможные дубли удаляются.
Метод реально работает. В декабре 2014 было чуть больше 2900 дублей replytocom, на сегодня осталось 1395…
Ещё раз спасибо за подсказку удалить это из роботс!
Зашла в поиске решения с индексацией фидов. При добавлении перенаправления в .htaccess на странице фида появляется сообщение о циклической переадресации. Вариант с functions.php ничего не изменил — метатег noindex не появился на странице фида.
А в параметрах УРЛ в панели вебмастера Гугл есть интересное примечание: Никакие URL. Робот Googlebot не будет сканировать URL с выбранным параметром. Этот вариант рекомендуется в том случае, если на сайте используется несколько параметров для фильтрации содержания. Так, если сообщить роботу Googlebot, что он не должен сканировать URL с менее существенными параметрами, такими как pricefrom и priceto, например,
то можно исключить сканирование содержания, уже доступного по адресу без этих параметров, например,
Получается, исключая страницы с /feed можно исключить сканирование собственно записи, с которой этот фид формируется.
Перенаправление в .htaccess заработало )
Да, перенаправление работает. Робот переходя по ссылке с feed, с помощью редиректа попадает на оригинальную страницу, которую необходимо проиндексировать. Поэтому такие страницы не должны попадать в индекс поисковой системы.
Василий, может быть, существует способ запретить формирование этих ссылок с фидом в исходном коде? Куча перенаправлений в блоге тоже не лучший вариант.
Жанна Лира, к 301 редиректу поисковики очень хорошо относятся. Я думаю, что ваши опасения напрасны.
Я обратила внимание что вы часто даёте внешние ссылки на скачивание различных программ. У вас эти ссылки обёрнуты в ноиндекс. Вы это с помощью плагина сделали или вручную?
Олеся, раньше у меня стоял плагин WP-NoRef, который закрывал все внешние ссылки в noindex, nofollow. После того, как я удалил плагин, я стал это делать вручную.
Читала сейчас и пыталась все пошагово повторить. Василий, спасибо вам огромное. Буду отслеживать результаты.
А у меня еще в параметрах гугла есть такое : wptouch_switch 118 , и redirect 118, и все на усмотрение робота. Может тоже это стоить поменять?
У вас установлен плагин WPTouch? Это относится к его настройкам, что это именно обозначает не знаю.
Да, установлен. А redirect?
Пусть с redirect все будет по умолчанию, чтобы ничему не навредить. Поисковый робот сам разберется, что ему делать.
Установила плагин древовидных комментов, а у меня при нажатии на кнопку ответить выдается ошибка. Вы не знаете, что это?
Алла, я не пользовался этим плагином, поэтому ничего подсказать не могу.
Василий, здравствуйте. Давно озадачилась проблемой дублей. Все как-то не хватало духу сделать сразу везде и все. И вот, по Вашей статье решила довести начатое до конца.
Сначала (самое простое) я просто отключила древовидные комментарии и в роботсе убрала Disallow: /?.
А сегодня, читая статью, вставила код в htaccess. Добавила в Параметры URL replytocom.
Вот вопрос: если в параметры добавить ещё и feed, то что ещё надо сделать? В роботсе?
И вот застряла на functions.php… Перед каким конкретно закрывающим тегом ?> надо ставить код? Их там куча!
И ещё вопрос: чтобы все-таки в комментах у меня была кнопочка ответить (и она не создавала дублей) мне после всех этих действий можно будет включить древовидные комментарии? Или надо ставить плагин? Что-то не хочется…
Светлана, а у вас в файле robots присутствует Disallow: /?s=
Удалите эту строку. Изменения в файле роботс зависят от того, какой именно код вы добавили в htaccess (в статье два кода), а также от наличия в выдаче вашего сайта других дублей.
Код вставляется в самом конце файла functions.
Если вам трудно понять, что нужно делать, то решить проблему replytocom можно еще другим, более простым способом. Установите этот плагин:
Плагин закроет ссылки с комментаторов (переходы на сайты будут работать), и удалит replytocom из кнопки «ответить».
Код в htaccess оставьте, включите древовидные комментарии.
Василий, в выдаче выходит 21 дубль replytocom
1. Строчку из роботса убрала.
2. В htaccess вставила вот этот код:
RewriteCond %{QUERY_STRING} ^replytocom= [NC] RewriteRule (.*) $1? [R=301,L]3. В файл functions.php поставила перед последним тегом ?> код
function replace_reply_to_com( $link ) { return preg_replace( '/href=\'(.*(\?|&)replytocom=(\d+)#respond)/', 'href=\'#comment-$3', $link );} add_filter( 'comment_reply_link', 'replace_reply_to_com' );4. В консоли в настройках обсуждения поставила галочку «разрешить древовидные комментарии».
5. Появились кнопочки «Ответить», но при наведении на них в левом нижнем углу появляется ссылка с replytocom.
Что я делаю не так? Установку плагина рассматриваю, как последний вариант…
Василий, с момента написания предыдущего комментария и до этого времени мой файл htaccess снова принял прежний вид, как будто и не вставляла в него 301 редирект.
Что произошло? В комментариях мельком прочитала про плагин безопасности. Это случайно не AntiVirus? Он у меня стоит недавно.
Изменения в файле htaccess могут слетать при обновлении WordPress. Нужно будет проверять время от время содержимое этого файла.
Светлана, плагин AntiVirus тут совершенно ни при чём! Он не делает никаких изменений в Ваших файлах. Он лишь показывает где, по его мнению, подозрительный код. А уж что с этим кодом делать решаете только Вы. Сам плагин ничего не меняет, не удаляет и не добавляет.
Светлана, отлично, что все получилось.
1. Вы сейчас вставили код для кнопки «ответить», которая и формировала появление replytocom.
2. Другой код используется для борьбы со всевозможными дублями страниц на сайте. Этот код добавляет на страницы метатег роботс noindex, nofollow.
Необходимо будет убрать все запрещающие директивы из файла robots.txt для того, чтобы роботы попадали на те страницы, и видели запрещающий индексацию метатег.
Еще нужно будет посмотреть настройки СЕО плагина, чтобы там не было взаимоисключающих настроек. Постепенно дубли будут удалены с сайта.
3. Если вы подведете курсор мыши к ссылке в топе комментаторов, а потом в контекстном меню выберите пункт «исследовать элемент» (или что-то в этом роде, в разных браузерах называется по-разному), то внизу вы увидите код этой ссылки. У вас почему-то там две одинаковых ссылки на один сайт. Одна ссылка в noindex, а другая не закрыта.
Каким образом это у вас реализовано, я не имею представления.
Василий, спасибо, что так подробно отвечаете на все мои вопросы. Но я не все понимаю, о чем Вы говорите…
Запрещающие директивы из файла robots.txt вроде уже все убрала. На счет настроек СЕО-плагина — не поняла.
В настройках СЕО плагинов также есть пункты для закрытия отдельных параметров. Поэтому, если вы какие-то параметры закрываете (вставкой кода в разные файлы), то плагин в своих настройках, не должен препятствовать работе поисковых роботов.
У вас стоит SEO Platinum. Имейте ввиду, что этот плагин давно не обновлялся. Про его настройки я ничего не знаю, так этот плагин я не использовал.
Василий, скажите, что означает в Вашем роботсе строка Disallow: /internet-1254?
В свое время, в индексе Яндекса начали появляться дубли страниц такого типа. Причем, на самом деле таких страниц с цифрами на самом сайте не было. Эти дубли формировал rel=shortlink. Поэтому я добавил такую запись для их удаления. Этих дублей уже давно нет. Теперь можно будет удалить эту сточку из файла robots.
Файл роботс практически не работает в этом плане. Что только не пробовал. Даже появлялась такая мысль, что поисковики и создатели Вордпресс за одно. Спасибо за плагин. Сегодня же установлю.
Приветствую! Скажите, что означает эта функция — RewriteRule (.*) $1? [R=301,L] и почему она дублируется в htacess?
Это перенаправление со страниц с определенными параметрами на другие. Это завершающая часть кода, в первой строке должно быть еще что-то начинающееся с RewriteCond. Вставляется в файл htaccess. А где вы это еще нашли, если говорите, что это дублируется?
Я сам еще в этом разбираюсь… Но факт, к чему прописаны эти 2 параметра как одинаковые? Для replytocom пишут так:
RewriteCond %{QUERY_STRING} ^replytocom= [NC]
RewriteRule (.*) $1? [R=301,L]
Какого черта еще его — RewriteRule (.*) $1? [R=301,L] внизу повторяют? Я на примере Борисова смотрю… Походу, придется изучать параметры редиректа…
В этом коде RewriteCond — определяет условия для выполнения определеного правила, в данном случае для replytocom.
Каждая директива RewriteRule — определяет правила для механизма преобразований, в нашем случае, отдельно для страниц в url, которых есть знак вопроса, feed, comments, и т.д.
В конце кода определяются условия для attachment_id, а RewriteRule определяет правила выполнения данного условия. Данный RewriteRule не имеет отношения к предыдущим, он выполняет только относящиеся к нему правила.
Скажите, а если я, например, хочу прописать редирект только для feed и все, то как это будет выглядеть?
После RewriteBase / вставьте:
RewriteRule (.+)/feed /$1 [R=301,L]
Приветствую еще раз, Василий! У меня есть дубли для архивов (http:/…ru/2014/09/) типа таких, сам тег archive не виден в url, а эти архивы есть за разные месяца и годы, как тут быть? В вашей статье есть код: function meta_robots…
Если его попробовать вставить, как рекомендовано, он случайно на все другие страницы не добавит мета-тег noindex, follow?
После вставки кода, можно будет проверить соответствующие страницы на наличие мета тегов.
Василий, добрый день. Сижу с вашей статьей уже второй час. Не могу подступиться к этим дублям. Так как я плохо разбираюсь в таких делах, то решила удалить их первым способом. Правильно ли я буду делать
1. Сначала я добавлю параметры в гугл веб-мастер, такие, как replytocom, feed и page
2. Затем просто удалю эти параметры из роботса (то, что относится к блоку гугла) и на этом можно успокоиться?
Меня просто смутило, что в первом способе вы написали про удаление, а потом в способе с редиректом написали, что «Директивы удаляются в том случае, если вы будете использовать этот метод».
Там имелось ввиду то, что при помощи перенаправления робот переходит со страницы с дублем на оригинальную страницу. Постепенно такие страницы будут удалятся из индекса. Для того, чтобы поисковый робот переходил на страницы с дублями ему нужно открыть доступ в файле robots.
Лара, если добавите параметры в панель вебмастера и удалите директивы из файла robots, это только полдела. Появление дублей еще нужно предотвратить, чтобы они не появлялись снова.
Например, на этом сайте удалены директивы в файле роботс, используется редирект, плагин AIOSP добавляет метатег noindex, nofollow к страницам, которые создают дубли (навигация, архивы, рубрики и т.п.), вставлен код для предотвращения добавления дублей с replytocom.
Лара, перечитайте раздел статьи, в котором я пишу как это работает на моем сайте. Я немного подредактировал статью для того, чтобы вам было более понятно, что нужно делать.
Я просто сегодня и Максима мучила. Когда я удалила директивы из роботса, он мне посоветовал их вернуть. Да, статью сейчас перечитаю, честно говоря у меня целая каша в голове.
Лара, директивы удаляются из файла robots для того, чтобы роботы могли перейти на соответствующие страницы сайта. Там с помощью перенаправления они переместятся с дубля на нужную страницу, или увидят на такой странице метатег noindex, nofollow, который запрещает им индексировать такую страницу. Постепенно такие страницы будут удалены с поисковой выдачи.
Если запрет в файле роботс стоит, то следовательно, роботы не попадут на страницу и не выполнят нужные нам действия. Поэтому дубли останутся на месте.
Ой мама дорогая, все равно ни хрена не понятно.
В вебмастер я добавила директивы, теперь я эти директивы удалю роботса. А дальше я уже не могу врубиться, что делать? Просто это вам кажется, что все понятно. Для меня же в вашей статье разобраться трудно. Вы написали один способ, второй, третий… Лучше бы один, но конкретный и по шагам для особо одаренных.
Василий, вот сидела разбирала. Надеюсь что буду делать правильно.
1. В веб мастер директивы добавлены, у меня пагинация и реплитоком, а еще и фиды.
2. Теперь я должна в файл htaccess вставить код, который в вашей статье.
3. После этого я в роботсе удаляю директивы
На этом все.
В файл функцион ничего не ставлю, так как у меня сео пак и в нем стоят галочки. Правильно все?
Лара, все правильно. Еще можно будет добавить код в файл functions, чтобы вообще не добавлялись новые replytocom при нажатии на кнопку «ответить». На моем сайте это реализовано таким образом.
Уфф, с меня пот в три ручья) Но, как же приятно, когда чет делается. Итак, я установила код и страница у меня открывается без реплитокома. Мне чуть не понятно, что конкретно удалить из роботса. Подскажите пожалуйста.
Disallow: /page/
Disallow: /page
Disallow: */page/*
Disallow: */feed/*
Disallow: */feed
Disallow: /*?*
Disallow: /?*
Было еще Disallow: /*?replytocom я это удалила. Удалять все или что-то нужно оставить? А то удалю…
Все эти директивы и удалите. Посмотрите на мой файл роботс. Там закрыто только то, что в принципе вообще не нужно индексировать.
А у меня уже даже каши нет… Давно забросила это дело, сегодня посмотрела в поиске Яндекса последние статьи, опять по 3-4 строчки по каждому запросу! А я уже не помню, что я там наменяла в htaccess и даже вспоминать не хочется! Так запустила сайт! В очередной раз прихожу к мысли, что заниматься этим делом успешно может только человек, который разбирается в технических вопросах, или если есть кто-то, кто ведет техническую сторону сайта, а ты только статьи пишешь.
Вот и думаю теперь, продлевать домены или нет. Но тем, у кого хватает упорства, желаю удачи!
Ну, у меня упорства хватает и я хочу научиться разбираться)
Галина, не нужно опускать руки. Это все не так сложно. Сделал один раз, а потом проверяй время от времени. Файл htaccess нужно будет проверять, потому что иногда после обновлений WordPress код может быть удален. Его тогда заново нужно будет добавить в файл.
Я же тоже не технический специалист по ведению сайта. Этот метод работает, поэтому я, в свое время и написал эту статью.
Но Вы разбираетесь в компьютерах! А мне, в отличие от Лары, даже разбираться уже не хочется, потому что технические проблемы вылезают постоянно, как тараканы из щелей, а мне даже времени жалко тратить на них. Вот и получается, переливание воды решетом.
Сейчас хочу в очередной раз поменять шаблон, в надежде, что в новом шаблоне не будет глюков и я смогу какое-то время поработать спокойно (но и сама в это не верю, если честно).
Галина, в новом шаблоне обратите особое внимание на поддержку мобильности и скорости его загрузки. Необходимо, чтобы там уже была полная поддержка мобильных устройств, скоро это будет очень важным фактором. А скорость загрузки прямо влияет на посещаемость. У разных шаблонов, еще без статей, она разная. Есть быстрые и медленные шаблоны. Поэтому необходимо будет выбрать быстрый шаблон.
Спасибо, Василий! Мобильная версия — это одна из главных фишек у автора шаблона и особая гордость, так что, с этим все нормально, я надеюсь.
Но на моих теперешних шаблонах стоит плагин, который обеспечивает мобильную версию, и вроде, нормально работает.
Можно с плагином, но это дополнительная нагрузка, которая прямо влияет на скорость загрузки сайта. Если на каких-то сайтах этот шаблон автора уже есть, то его можно будет поверить во всевозможных сервисах.
Приветствую! Есть проблема с кодом, о котором писал М.Зайцев:
Хотел оставить у него комментарий, а они у него не работают. Решил спросить у вас. Все сделал по статье и все работало, но потом отказывает открывать ссылки на сайты комментаторов, хотя они есть (не текст), как обновлю файл (footer.php или functions.php), начинает открывать, но вскоре опять отказывает. Можете подсказать, что такое может быть?
Я не пользовался таким способом для сокрытия ссылок, поэтому ничего не могу сказать по этому поводу.
Не, статья теперь понятная) Я просто посидела, выписала основные ваши шаги и сделала, застряла просто на роботсе.
Лара, вам в роботсе после Disallow: /wp-content можно остальное вообще удалить. Там некоторые директивы просто дублировали друг друга.
Василий, я поставила код от Антона Лапшина, но у меня все равно выводится в левом углу реплитоком. Это значит у меня этот код не работает?
Этот код должен работать. У меня он стоит и работает. Похоже у вас он вообще не действует, потому что замена не происходит.
Я разобралась. Я взяла код у Максима Зайцева, он у меня заработал.
Уфф, хочу вас поблагодарить за терпение и помощь. Вроде бы уже все сделала, ничего не упустила. Буду ждать результата.
А вы ссылки авторов комментариев не закрывали от индексации, например, в span, а то nofollow все равно индексируют поисковики.
У меня ссылка на сайты комментаторов закрыты в span. Это можно увидеть в исходном коде страницы.
Можно узнать, каким способом вы их закрывали?
Раньше закрывал кодом, теперь плагином Hide Links. Принцип действия в обоих случаях примерно одинаковый.
Василий, здравствуйте! Прочитала вашу статью у меня сейчас такая же история, как и вас была просел трафик с Гугла (где-то на 2000 посетителей в сутки уменьшился), возможно тоже из-за дублей страниц, хотя точно я не знаю. Но дублей страниц очень много, хотя вот тех что replytocom я проверила только 52 результата выдает. 301 редирект не стала прописывать, сделала, как вы написали через панель гугл вебмастер, добавила туда replytocom. Подскажите, я что-то не совсем поняла, а как остальные дубли удалять, те что не replytocom, как от них избавляться? Да и я ещё поменяла robots.txt поставила такой же как у вас, сейчас стоит на блоге, не знаю может тоже это не совсем правильное решение, подскажите пожалуйста?
Елена, я произвел на своем сайте такие действия:
1. Изменил файл robots.txt. В этом файле я открыл для индексации соответствующие директории на своем сайте.
2. Добавил параметры replytocom в панель веб-мастера Google.
3. Добавил в файл htaccess соответствующие команды для перенаправления поисковых роботов на оригинальные страницы.
4. В файл functions.php был добавлен код для предотвращения появления новых дублей с переменной replytocom.
5. В плагине для СЕО оптимизации были отмечены пункты для добавления метатега роботс noindex, nofollow для соответствующих страниц моего сайта.
Все это в комплексе отлично работает. Например, в панели веб-мастера Google в декабре 2013 года, когда я начал только борьбу с дублями на своем сайте, в «статусе индексирования» было проиндексировано 7139 страниц, а в данный момент, через полтора года — 322 страницы. Как видите, положительный результат налицо.
Вы можете сделать так, как сделал я на своем сайте, или идти своим путем, методом проб и ошибок.
Василий, спасибо за ответ. Я много пересмотрела материала в интернете, ваша статья оказалась самой информативной по этому вопросу. Я ещё хотела уточнить, если у меня в индекс попали статьи с метками (tag), page, рубрики, тогда, если я правильно поняла, эти параметры тоже можно внести в панель гугл-вебмастер также, как вы описывали с replytocom?
И ещё, в вашем robots.txt не стоит сейчас запрет на индексацию tag, feed. Почему? Если они также создают дубли страниц.
Елена, в панель вебмастера у меня внесены только параметры replytocom.
Запрет снят в файле robots для того, чтобы поисковые роботы переходили на такие страницы.
В случае с feed, после перехода на страницу, робот с помощью 301 редиректа будет перенаправлен на «правильную» страницу. Для этого был добавлен соответствующий код в файл htaccess.
Для tag в настройках плагина AIOSP стоит запрет на индексирование — noindex.
Василий, у меня тоже стоял запрет на индексирование noindex в плагине AIOSP для tag и рубрик. Убрала запрет для tag и рубрик из robots.txt гугл моментально всё проиндексировал, наделав кучей дублей. Получается, что не всегда этот запрет действует, иначе чем тогда это можно объяснить
Вообще-то поисковики никогда моментально все не индексируют. Может быть эти дубли у вас уже были. Дубли из дополнительного индекса удаляются не сразу. Во всяком случае, ничего другого пока не придумали.
Когда я проверяю свой сайт, мене иногда попадаются дубли с рубриками в URL, а таких страниц на моем сайте нет уже года полтора. Все давно было переиндексировано. Я просто удаляю такие адреса вручную.
Василий, ну не сразу где-то дня через два. Я имела ввиду не названия рубрик в URL перед названием статьи, а сами рубрики. Сами рубрики ведь тоже дублируют контент на сайте. Разве нет?
Вот я сделала экспресс анализ сайта в сеолиб, результат: 59%. Высокий процент страниц в Google Supplemental. Возможно, на сайте имеются внутренние дубли страниц или не уникальный контент. Всего лишь несколько дней назад такого не было.
А tag я всё таки поставила на удаление в гугл вебмастер. Хотела узнать ваше мнение, может быть проиндексированные рубрики удалить вручную (их ведь немного), а потом опять их закрыть в robots.txt?? Хотя почитала у вас тут в комментариях, советуют ничего не удалять через гугл вебмастер вручную, написано, что сайт может вылететь из индекса.
По рубрикам я вас правильно понял. Это я привел вам пример, что таких страниц уже больше года нет, а потом вдруг в дополнительном индексе появляется страница с такими параметрами, значит Google откуда-то их откапывает.
Елена, не следует слепо доверять показателям подобных сервисов. Ориентируйтесь на показатели Яндекса и Google. Например, Сеолиб показывает, что в Гугле у меня в индексе 394 страницы, а вебмаcтер Google — 325 страниц. Сервис от таких неточных данных, высчитывает количество страниц в дополнительном индексе. Поэтому точные показатели даст только поисковая система.
Я удалял вручную некоторые страницы, по 10-15 штук в день. Как видите, ничего не произошло.
Василий большое Вам спасибо, я вас поняла, действительно несоответствие присутствует. У меня ещё один вопрос. Вчера я добавляла URL на удаление в панели вебмастера гугл, сегодня посмотрела этих URL уже нет в панели гугла. Но вот проверила по некоторым URL из индекса ничего не удалилось, т.е. я вставляю ссылку в браузер она открывается, все как и было раньше. Почему так, или должно пройти какое то ещё время, вы не помните, как у вас было?
Подождите некоторое время, но все моментально происходит. Дубли удалятся не сразу, а постепенно.
Василий, здравствуйте! Возник ещё вопрос по параметрам на удаление. Вот я добавила параметры на удаление в Гугл вебмастер , на сколько я поняла в графе количество отслеживаемых URL должны напротив параметров стоять цифры, у мня ничего нет, просто стоят прочерки. Настройки выставляла, как написано у вас в статье. Получается, что робот не видит эти дубли или как тогда? Может быть надо ещё поставить запрет на эти параметры в robots.txt ? Я что то окончательно запуталась.
Елена, Google нам пишет, что:
Поэтому, здесь будет лучше ничего кардинально не менять. Добавьте туда replytocom, я думаю, что этого будет достаточно. Процесс удаления дублей не быстрый, нужно будет потерпеть некоторое время для того, чтобы увидеть положительные результаты.
Здравствуйте, подскажите пожалуйста, на моем блоге имеются страницы со ссылками, где на конце добавлены вот такие окончания: «?m=1». Скажите это ведь тоже дубли страниц? Просто если перейти по одной из этих ссылок, то по ней страница моего блога будет отображаться в пол экрана, и я подумал что это просто ссылка на мобильную версию.
Прочитайте, возможно, это ваш случай:
Статья конечно полезная, но не по моей части. Там написано, что URL мобильной версии выглядит вот так: «m.example.com». То есть m стоит вначале ссылки, а у меня она наоборот, стоит в конце, вот пример одной из ссылок с моего блога:
Но я уже отправил запрос на удаление таких ссылок, теперь жду переиндексации.
Здравствуйте Василий. Прошлый год я все сделал как написано в статье. Все страницы с дублями улетели из поиска. За это Вам спасибо. Сейчас смотрю и вот что показывает гугл.
Мы скрыли некоторые результаты, которые очень похожи на уже представленные выше (6). Опять появился feed/ и так stoimost-i-ceny/feed/atom/
Просто в шоке что опять не так? Скажите пожалуйста.
Вот еще один вопрос что вы думаете про дубли в Яндексе:
Страниц в поиске — 221
Загружено роботом — 500
Исключено роботом — 278
Мне волнует вот это: Документ является неканоническим — 214 страниц
В этом разделе находится информация о страницах, которые не были проиндексированы роботом при посещении сайта. Часто индексирование страниц намеренно запрещается вебмастером – это не является ошибкой и исправления не требует. Иногда могут возникать неполадки на стороне вашего сервера или сайта, что ведет к нежелательному исключению страниц, в этом случае проблему рекомендуется устранить.
В настройках вы самостоятельно можете указать, к какой категории относится та или иная причина исключения.
Страницы запрещены к индексированию вебмастером или не существуют
HTTP-статус: Ресурс не найден (404) — 19
Документ запрещен в файле robots.txt — 44
Документ содержит мета-тег noindex — 1
Документ является неканоническим — 214
Иногда, дубли могут появляться. Это нормально. Потом они опять будут удалены.
А вы посмотрите, что за страницы являются неканоническими. Тогда будет понятно, что это за страницы и что с ними делать.
Да и посещаемость упала на 50%. И боюсь что будет с моего сайта
Вам нужно разбираться, с каких поисковых систем упала посещаемость, по каким причинам. Скорее всего, дубли тут не причем.
Василий, здравствуйте! Хотела спросить, а зачем закрывают от индексации комментарии Disallow: */comments/, какой тогда от них прок?
Может быть для того, чтобы сделать статью более уникальной, также может быть для того, чтобы не индексировался спам в комментариях. Я предполагаю, что большинство блоггеров такую директиву просто скопировали у других, не задумываясь над ее смыслом.
По моему мнению, комментарии закрывать не нужно. Если там все по делу, то это работает на продвижение статьи.
Вот и я такого же мнения, мне кажется хорошие комментарии, наоборот, способствуют продвижению статьи, а спам можно просто удалить. А комментарии не могут, как-то создавать дубли страниц, если они открыты для индексации, как вы считаете?
Если появится такая страница, то с помощью 301 редиректа робот будет направлен на основную страницу. Со временем такая страница будет удалена из индекса.
Подскажи пожалуйста, у меня есть вот такие ссылки пагинации:
соответственно это дубли страниц пагинации и гугл с яндексом их хорошо кушает и все они в индексе, как сделать 301 редирект на
или закрыть от индексации?
Вам нужно будет закрыть пагинацию в SEO плагине, или при помощи последнего кода из этой статьи. Только уберите из файла robots.txt директивы с вопросами, иначе метатег роботс не будет работать.
В том то и дело, что пагинацию я не хочу закрывать в noindex. Может есть другой способ, второй день уже сижу, весь инет перерыл?
В вашем случае, поможет наверное только переадресация. Конкретный код подсказать не могу, так как у меня нет возможности воспроизвести добавление в ссылке, чтобы проверить код на работоспособность.
Василий помоги с 301 редиректом, буду тебе очень благодарен.
Возьмите за основу этот код, вставьте его выше других правил:
RewriteCond %{REQUEST_URI} !(/page*) RewriteRule (.*)\/([0-9]+/)$ /$1 [R=301,L]Поредактируйте вторую строчку. Может быть слэш нужно будет убрать после плюса.
Василий от души тебе благодарен за помощь, всяко перепробовал, не фига не работает?
Обратитесь к компетентному специалисту. Я всего лишь любитель в этой сфере.
Василий здравствуйте! Подскажите пожалуйста, если набираешь site:site.ru comments (site.ru домен сайта), то выходят все статьи, где присутствуют комментарии. Эти страницы являются дублями или нет?
Нет. У вас же в адресе ссылки нет comments.
Большое спасибо за подсказку по редактированию functions.php На днях начал борьбу с дублями, и ни как не мог понять, куда нужно прописать изменения в этом файле, «реплетуком» в ссылке оставался. Сейчас сделал как указано у вас, прописал в самом конце. Теперь вроде как надо. Надеюсь поможет в борьбе)
А как убрать дубль в таком случае:
сайт/страница
сайт/страница/
Как оставить что-то одно?
Сделайте 301 редирект в файле .htaccess.
Со страниц без слеша на страницы со слешем:
RewriteCond %{REQUEST_URI} !\? RewriteCond %{REQUEST_URI} !\& RewriteCond %{REQUEST_URI} !\= RewriteCond %{REQUEST_URI} !\. RewriteCond %{REQUEST_URI} ![^\/]$ RewriteRule ^(.*)\/$ /$1 [R=301,L]Наоборот, со страниц со слешем на страницы без слеша:
RewriteCond %{REQUEST_URI} !\? RewriteCond %{REQUEST_URI} !\& RewriteCond %{REQUEST_URI} !\= RewriteCond %{REQUEST_URI} !\. RewriteCond %{REQUEST_URI} !\/$ RewriteRule ^(.*[^\/])$ /$1/ [R=301,L]Василий, здравствуйте! Завис на Вашем сайте, хотя мой сайт о ремонте и строительстве, но все равно что то приходится делать самому по сайту. Ваши советы и рекомендации открыли мне много того, о чем и не подозревал. Спасибо за информацию, теперь я Ваш постоянный читатель. Буду пробовать внедрять знания на своем сайте.
Владимир, успехов! Все мы все время учимся чему-то новому.
Василий, есть такой вопрос, после перехода на https обнаружила, что Гугл в поиске выдает страницы с http и те же самые страницы с https. Это считается дублями страниц, что с этим делать? Может удалить вручную?
Это не дубли, Google сам их исключит из поиска.
Добрый день! Статья очень пригодилась, спасибо. Добавил в закладки. Остался вопрос, вот вы пишите: «В Яндекс соотношение количества загруженных роботом страниц и страниц в поиске на моем сайте, на данный момент, оптимальное».
А какое отношение считается оптимальным?
У меня загруженных 1500, а в поиске 350. Это нормально или говорит о том, что робот грузит лишние страницы?
Войдите в Яндекс Вебмастер, в разделе «Индексирование» откройте «Структура сайта». Там вы увидите, что именно было проиндексировано на сайте, и что добавлено в поиск. После анализа этой информации, сможете сделать выводы.
Замечательная статья, благодарю!
Здравствуйте, интересная статья, но не нашла ответа на проблему с которой я столкнулась на своем сайте. Может, подскажете? Яндекс ругается на страницы типа /wp-content/uploads/2018/02/ — «одинаковые заголовки и описания страниц».
Я даже и не знаю, как описания добавить на страницы такого рода в WordPress. Но не уверена, что эти страницы в индексе помогают посещаемости. Можно попробовать закрыть /wp-content/uploads/ для индексации, но тогда картинки не будут индексироваться.
Наверное, нужно установить атрибут rel=”canonical” на эти архивы с изображениями, чтобы он указывал на папку «uploads», или установить на них meta name=”robots” content=”noindex”.
Обычно, это настраивается в SEO плагине.